


|
|
|
Our sponsors make financial contributions toward the costs of publishing Linux Gazette. If you would like to become a sponsor of LG, e-mail us at [email protected].
Write the Gazette at [email protected]
|
Contents: |
 Date: Mon, 18 Aug 1997 00:25:47 -0400
Date: Mon, 18 Aug 1997 00:25:47 -0400
From: Anthony Wilson [email protected]
Subject: Difficulty running programmes
I am using Linux Slackware 3.0 with kernel version 2.0. I am running a LAN and whenever I try to run a script or a program that I created on the server, I get a command not found error, even though I have read write permissions on the file in my own directory. If I transfer that same file to another Linux box on this LAN, I can run it without any problems.
Is there an easy fix to this problem?
Thank you.
Anthony Wilson
Date: Wed, 20 Aug 1997 06:00:38 +0200
From: Denny [email protected]
Subject: Connecting to dynamic IP via ethernet
Hello. I want to connect my Linux box to our ethernet ring here at my company. The problem is that they(we) use dynamic IP adresses, and I don't know how to get an adress. I use win95 on one partition on my pc, from where it works fine to connect. I know the IP adress to the DCHP-server (that the one who distributes the IP-adresses, right?) but how do I do to get assigned an IP-adress from Linux? I got so tired of trying, that I finally just assigned an adress myself and hey, somethings work. I can use telnet and ftp but X takes 15 minutes to start, and emacs likewise. I can't wait that amount and also I'm sure there are several thing that don't work. Please, if you know how to do, explain carefully, I'm not all that good at linux and tcp/ip hacking.
Denny
Date: Fri, 15 Aug 1997 09:47:03 -0500
From: Cory Sticha [email protected]
Subject: Printing PostScript to a DeskJet 682C
I've got a question that I'd to have answered. I've got an HP DeskJet 682C printer that I'd like to use to print pages out from Netscape. Unfortunately, the printer only recognizes text and PCL 3, while Netscape only uses PostScript. Is there a filter that is capable of converting PostScript to PCL 3. Also, to print text to this printer, I have to pipe the file that I want to print to todos and then pipe that to the printer. How can I automate this? Thank you very much in advance for any help that you can give me.
Cory Sticha, SrA, USAF
Date: Mon, 04 Aug 1997 14:12:42 +1000
From: Marcus B [email protected]
Subject: Problem with adaptec 2940U
Answer: RedHat versions <4.0 use older kernels which don't have aic7xxx support, I found this out the hard way, back when the aic7xxx driver was only being developed, if you are talking about a version of RedHat that uses 2.0.x kernels, then they get loaded in as a module (when it asks what type of SCSI host adapter you have), if this is not loading then it might be an idea to check if it is sharing an IRQ with another device in windows 95 (if you are unlucky enough to have it!), and manually change it. The aic7xxx driver is very new (>2.x kernels only) but there are problems on some hardware configurations.
Date: Wed, 6 Aug 97 20:55:49 BST
From: George russell [email protected]
Subject: Linux Help needed to connect to Internet
I am a new Linux user, and inexperienced in Unix environments. My aim in using Linux is to connect to the internet without needing to use Windows, in order to learn about Linux and update my linux setup (Slackware Linux Toolkit March 1997, which I will install again soon). I have had X Windows and Netscape Navigator 3.01 installed,and will do so again after a hard disc upgrade. I am unable to connect to the internet. Could anyone help me to do this? My modem is on COM2, and works under windows as a generic modem. I know the number of my ISP, that my IP address is server assigned. I have the IP addresses of the primary and secondary DNS, and have my own username and password. Is there anyhing else I need to know, and can anyone help me with this? I would be very grateful for all assistance given.
Date: Wed, 06 Aug 1997 15:35:20 -0700
From: Luke [email protected]
Subject:LILO Problems
I have this 2 gig scsi drive. I have Linux and Windows 95 on my system.
95 is on the first gig and Linux is on the 2nd. Lilo gives me problems
with booting Linux from the second gig. And windows just will not see it.
Its a old scsi disk. So I cant use sector compadibility mode. Right now.
I use Lodlin (and some 95 proggy) to drop out of 95 and kick linux in.
Eather this or I have to use a installation floppy (I cant load lilo on
a floppy because it gives me disks problems there too) You know of any
boot managers that I can gain access to that can read the entire disk? I
know the NT boot loader can do this. But there is no point in loading NT
for this task.
Another problem I have is this. I have a Windows NT box as a proxy
server for my internet connection. (I can't convert it to Linux, it's not
my box) I can get Windows 95 to send all ip requests threw the proxy
using the ms proxy client. (ex: quake over the net) But with Linux I
can't seem to do that. I have used Netscape a bit for this purpose. But I
still can't do anything else. Is there a way to get Linux to work over a
proxy itself? I could just dail into my ISP va PPP. But I already have
a 10 megabit connection to them. What's the point of using a modem. Is
there a way I can get around this problem?
Another question I have is can I make a swap from an image or some other
media. I don't want to kill my Linux partition to gain this. But, I have
a 16 meg swap partition and 16 megs of ram. Trying to run progams like
Wabi is of no use. They don't seem to have enough memory. Is there a way
to add more swap space with out disturbing the exsisting partitions?
Well thank you for your time.
Long live LINUX!!!
Luke Holden
Date: Sat, 09 Aug 1997 23:14:04 -0400
From: David Nghiem [email protected]
Subject: Pointers
Hey all,
Do you guys know of any information regarding programming a game in Linux on the X11 platform? I want to use it as a cross developer for some DOS games. The main issue here is this: How do I display my output?
Laterz,
Dave.
Date: Fri, 08 Aug 1997 20:03:21 -0400
From: Raymond E. Rogers [email protected]
Subject: Apllixware -- Fax
I bought applixware some time ago and found that I was supposed to roll my own Fax interface. Somebody at work suggested just setting up a "printer" for fax. Logical to me. As I don't do Linux for a living or a hobby; it would be nice if somebody could write and article on how to do it. Or point me to instructions. I looked around and was unable to find any.
There is supposed to be instructions in how to make netscape do standard PGP/RSA digital signatures that can be verified on any PGP system, not just inside of netscape. Simple instructions on this would be nice.
If I get around to doing these things first, I will write an article on how I did it.
Enjoy
Ray
(An article entitled "Faxing from the Web" will be included in the upcoming November issue of Linux Journal. While the magazine won't be out until next month, the listings that go with it (including his front end) are available at http://www.ssc.com/pub/lj/listings/issue43/2044.tgz. Since the author was not using Applixware, I'm not sure how much his code will help, but check it out, it may be just what you need. --Editor)
Date: Wed, 30 Jul 1997 12:22:41 -0700
From: Tom Schenck [email protected]
Subject: Organize and overtake!
Well, I'm pretty sure there are people doing this, but not very fast or efficiently. We need a stable, friendly, easy-to-install system that comes equiped with applications that allow the user to begin working right away, and configure without programming knowledge!
Yes, it's *nix. Yes, it's a programmers environment. Yes, it doesn't HAVE to be terse, hard to configure, etc.
Hell, maybe I'll have to do it!
Date: Fri, 22 Aug 97 21:09:09 BST
From: Duncan Simpson feynmen.ecs.soton.ac.uk
Subject: M$ word
Those who need to read a word document might like to get the latest version of wqord2x by anonymous ftp from amil.telstar.net in the pub/duncan directory. Note the machine's main job is a mail redirection service, which sends me the logs, amoung other things!!
Duncan
Date: Sun, 10 Aug 1997 13:56:23 -0600 (MDT)
From: Michael J. Hammel [email protected]
Subject: MS quote
This comes via a Mac friend of mine. We should look closely at aligning with the Mac users of the world. They hate MS almost as much as we do. :-) From: EvangeList [email protected] This tidbit is from: Dave Reiser, [email protected] In a page 1 article in the July 28, 1997 Computerworld there's an article ENTITLED "Microsoft Declares War" about how MS has announced that it will not ship the Java class libraries. I absolutely howled when I read this quote: "'We have no intention of shipping another bloated operating system and forcing that down the throats of our Windows customers'" [attributed to Paul Maritz, Microsoft Group Vice President] Are they feeling guilty about the fact that they've already rammed one bloated operating system down their customers' throats? -- Michael J. Hammel
From [email protected] Fri Aug 8 21:48:52 1997
Date: Fri, 08 Aug 1997 23:00:22 -0600
Subject: Descent 3D for Linux?
Linux has always been the perfect platform for games, it's just very few developers (id and Crack.com are the only two worth mentioning that I know of) know that.
Actually I think many of the developers know the value of Linux, but there is no marketing proof that a Linux port will make money. As many others have said in the past, we need certifiable numbers to prove the market exists and that its willing to spend money on commercial products. I don't have any info on it, but I'd love to know if either Id or Crack.com made any money on their Linux ports. And I'd like to know if it was enough, in their eyes, to warrant future ports. I've a gut feeling the Id guys may have done their port simply because they liked the idea and did it for fun, but thats just an unsubstantiated hunch.
I just got back from SIGGRAPH today and after having talked to many engineers from lots of different companies I can say that nearly all are *very* aware of Linux and most (that I talked to) are using it. One engineer from Cosmos Software, the new division at SGI, said they'd probably be happy to let someone do the port of the new Cosmo Player 1.0 to Linux (although he wasn't sure how to go about getting that done). Most of the companies at the conference who are Unix aware are also Linux aware. They just need a little proof that the market will return their investment within a reasonable time frame.
One of the things I decided to do while I was at SIGGRAPH was to write an article outlining how to begin to get reasonable market figures for Linux with respect to graphics tools and games (other vertical markets are a bit out of my league). I'm sketching this out now and will probably submit it to the Linux Journal in September or October. Much of it resolves around the use of simple Multimedia applications. Anyway, once we have the numbers to back us up, it will be a little easier to convince game developers to include Linux ports of their software.
-- Michael J. Hammel
Date: Fri, 08 Aug 1997 22:36:23 -0600
From: Michael J. Hammel [email protected]
Subject: Firewire and DV
I just got back from SIGGRAPH. To my knowledge there are no plans for Firewire support for Linux, but I have to admit I didn't specifically go looking for it. I'm not even completely sure what it is (although thought it was just another 3D chipset). I've been on a personal crusade to get Linux noticed as a terrific platform for image processing and graphic arts tools, and that includes (eventually) Digital Video (DV) tools. However, although there are quite a large number of tools for doing computer graphics (including plenty of support for OpenGL, both commercially and in the freeware MesaGL package), I've not seen any DV style tools. I'd say its a little early for such tools on a commercial basis since more basic tools are not commercially supported yet. But its certainly something I'll continue to keep an eye on and do my best to encourage.
DV tools would work as well on Linux as any other high-end Unix system, but tools like graphics tablets and scanners need better support before we'll get into DV tools. We also need a decent GUI toolkit. Motif is ok, but a bit bloated. Most of the other toolkits don't have enough printed documentation available yet. While at SIGGRAPH, Mark Kilgard told me that there is a new toolkit that sits on top of GLUT that might be a good basis for a more advanced toolkit. I haven't had time to look at it yet (I just got back today). Anyway, I hope this helps a little. If you find any DV tools or have contacts that could use a little polite prodding, feel free to drop me a line.
-- Michael J. Hammel
Date: Wed, 27 Aug 1997 09:04:22 -0700 (PDT)
From: Riley Eller [email protected]
It took Linus to make it happen
It took everyone to make it right
It takes HOWTOs to make it work
It takes the Gazette to make it FUN
Thank You Linux Gazette :-)
Riley Eller
Newbie Jihad Warrior
![[ TABLE OF
CONTENTS ]](../gx/indexnew.gif)
![[ FRONT
PAGE ]](../gx/homenew.gif)
 More 2¢ Tips!
More 2¢ Tips!
 Changing Video Modes
Changing Video Modes
Date: Fri, 08 Aug 1997 22:41:05 -0600
From: Michael J. Hammel [email protected]
I don't know how AccelX and XiGraphics and MetroX handle these things.
AccelX is ( I think) a PC graphics company. You might mean Xaccel, which is the actual program name for Xi Graphics X server. Its product name is "AcceleratedX". Xi Graphics is the company name.
As for how Xaccel changes its video modes - try CTRL-ALT-+ (thats a plus sign). I believe that cycles through the various modes. Check the man pages or manual to be certain. I believe MetroX does similar, but the keystroke is probably different.
--
Colormap Question
Date: Fri, 08 Aug 1997 23:47:31 -0600
From: Michael J. Hammel [email protected]
The question was "can you force an X application to use its own colormap in some way other than using a command line option". The answer is: it depends (aint it always the case?).
An applications ability to use its own colormap is not a "builtin" part of X. Colormaps are part of X, but the application still has to add code to make use of colormaps. So if the application doesn't have any code specifically for handling colormaps (for example, my XPostitPlus doesn't have any such code) then neither the command line or any other method will force it to use a private colormap. The default for applications (like XPostitPlus) is to use the default colormap, and thats why you often see applications with weird colors that you can't get rid of till you exit some other application.
Now, if the application *does* have code to deal with colormaps, it can also make the use of the private colormap a user configurable option. X provides a mechanism for making an option either a command line option (eg. -usePrivateColormap) or an X resource. X resources can be specified in X resource files (like .Xdefaults) or on the command line using the -xrm option. X is so configurable that the number of ways for a user to supply configuration information can often be quite confusing, both for the user and the developer. In any case, its up to the programmer to make any of these methods available. None is available by default simply becaue its "an X windows program".
The correct thing for an application to do is to allow the user to configure the use of the private colormap in at least one way and to provide a best-guess default for determining if a private colormap would be the best thing to do or not if the user doesn't provide a preference. Few applications do this, however. The GIMP does. So do XV and Netscape. Even my own programs aren't very good at this, although I intend to get much better in the very near future.
As for an X column, well, I'd love to see one. We just need to convince some X hack to spend a little time writing articles instead of code. Thats kinda hard to do. I'll probably be adding some X coding tidbits to my Muse column, but only with respect to using Motif or OpenGL in graphical and multimedia applications.
Hope this helps a little.
-- Michael
Netcat!
Date: 01 Aug 1997 15:46 EDT
From: Jean-Philippe Sugarbroad [email protected]
I was going through back issues of the Linux Gazette and I remembered a program I use quite frequently... netcat. This program enables you to open sockets and connect or listen with them - all from a shell script! It's a great way to quickly fetch web pages or see if a server is running... It even has UDP 'connection' mode and zero-io mode (which closes the connection as soon as it succeeds...). The UDP mode even uses a TCP connection to check round-trip time :) I love it!
Jean-Philippe Sugarbroad
Starting and Stopping Services
Date: Tue, 5 Aug 1997 18:55:19 -0600 (CST)
From: Terrence Martin [email protected]
I was just reading the August version of Linux Journal and I noticed refrence to rebooting the system after making changes to the /etc/syslog.conf file in order for those changes to take affect. This is contrary to a feature that is the main reason I use Linux at home and at work.
It is only generally necessary to reboot Linux to add/remove hardware or when installing a new kernel. In the specific case of syslogd(8) you can inform the server to reread it's initialization file by sending it a SIGHUP signal.
eg. kill -HUP `cat /var/run/syslogd.pid`
This will work with many of the servers available for Linux including (most) httpd(8), named(8), and inetd(8).
Sometimes however it is preferable to actually restart these services. In Slackware I believe most of your services are placed in a single script and this makes it a little more difficult to pick and choose which services to stop and start.
In RedHat it is a little more modular. In the directory /etc/rc.d/init.d are the scripts that are run on bootup to start various services.
These scripts allow you to start and stop various services just as if you had shutdown and rebooted your machine. eg.
# /etc/rc.d/init.d/named.init stop # /etc/rc.d/init.d/named.init start
This will start and stop the name service.
The scripts supplied with RedHat are not too complex compared to similar scripts I have seen on other systems. They can usually be adapted to new services that you may wish to have start on bootup, without complicating the rc.local file and giving you much finer control.
If you examine the soft links in /etc/rc.d/rc0.d through /etc/rc.d/rc6.d you will notice that they link to the files in /etc/rc.d/init.d. Each of these numbers on these directories refer to a "runlevel".
As the system boots the /etc/inittab tells the init process which directories to examine to determine which services to start up, most systems not running xdm will end at runlevel 3, otherwise it is runlevel 5.
All of the files(softlinks) in runlevel 3 beginning with 'S' are executed in order of occurance in the directory, this is controlled by giving each a number ie
S30syslog -> ../init.d/syslog comes before S40cron -> ../init.d/cron.init.Note: Links with the same number are executed in lexical order.
The sequence may be important depending what services depend on other services.
I put most of the services I add in runlevel 3, as I usually boot into multiuser mode. You then should add the approriate script link to /etc/rc6.d as those are the files that are executed on shutdown. Note the convention here is to begin all soft link names with 'K'. ie
K10named.init -> ../init.d/named.init
Again these scripts are executed on order with the highest number being last to run.
The net effect of all these links is that with an 'S' preceding the soft link the script is run with the argument "start" and with a 'K' it is run with the argument "stop".
Over the last two weeks I have set up and configured a news server, web server, name server, sshd server, updated the syslog.conf file plus a hundred other little tweaks on our RedHat 4.x box and I have not had to reboot once. In fact the system has not been rebooted since we added a new CPU and SCSI card 31 days ago...I love Linux :)...
Regards
Terrence Martin
A New Tool for Linux
Date: Fri, 22 Aug 1997 08:29:59 -0500
From: Ian [email protected]
The version posted in issue 20 assumes you have exec access to ALL dirs under the one you 'TREE'
Here's a modified version which works even in cases of unreadable folders:
-------------------------------- cut here --------------
#!/bin/sh
# @(#) tree 1.1 30/11/95 by Jordi Sanfeliu
# email: [email protected]
#
# Initial version: 1.0 30/11/95
# Next version : 1.1 24/02/97 Now, with symbolic links
# Patch by : Ian Kjos, to support unsearchable dirs
# email: [email protected]
#
# Tree is a tool for view the directory tree (obvious :-) )
#
search () {
for dir in `echo *`
do
if [ -d $dir ] ; then
zz=0
while [ $zz != $deep ]
do
echo -n "| "
zz=`expr $zz + 1`
done
if [ -L $dir ] ; then
echo "+---$dir" `ls -l $dir | sed 's/^.*'$dir' //'`
else
echo "+---$dir"
if cd $dir ; then
deep=`expr $deep + 1`
search # with recursivity ;-)
numdirs=`expr $numdirs + 1`
fi
fi
fi
done
cd ..
if [ $deep ] ; then
swfi=1
fi
deep=`expr $deep - 1`
}
# - Main -
if [ $# = 0 ] ; then
cd `pwd`
else
cd $1
fi
echo "Initial directory = `pwd`"
swfi=0
deep=0
numdirs=0
zz=0
while [ $swfi != 1 ]
do
search
done
echo "Total directories = $numdirs"
-------------------------------- cut here --------------
The changes are to put the "cd $dir" as the predicate of an IF statement, NOT IN A SUBSHELL, and the recursive part is the switched clause. This prevents infinite recursion in the case of an unreadable or unexecable dir.
Of Logs and Other Things
Date: Sun, 10 Aug 1997 21:47:39 +0200
From: D. Emilio Grimaldo T. [email protected]
Hi,
I recently saw on the August issue of Linux Gazzete and some
previous issues about the handling of system logs. Well, it
doesn't have to be complicated, in fact I have written a very
useful script/package that has been around for a couple of
years, it is called Chklogs and is used by major network providers,
companies and small-time users of Linux systems. In fact it is
going to be featured in the Linux Journal some time this year.
IT fulfills all the log handling needs. For more information
see
http://www.iaehv.nl/users/grimaldo/info/
Catch the link to Chklogs
Best Regards,
Emilio
Calculator Tip
Date: Sun, 27 Jul 1997 23:43:37 +0200 (MET DST)
From: Hans Zoebelein [email protected]
Hello Linux Gazetters,
Here comes a real cheap command line calculator.
Since shell scripts do only integer calculation,
you are stuck if you want floating point precision.
You also want to do sometimes stuff like 'how much is 1200*3/7' at the commandline without firing up a full blown GUI calculator.
Just for that work you can use the calcme command line calculator, which is hacked in perl. Dont forget that a shell thinks differently about 10*3 than a calculator. So do it as 10\*3 or "10*3".
The icing of the cake is the optional formatting. If you supply something like %.3f as second parameter, the output is nicely formatted as floating point number and up/down rounded correctly after 3 decimals.
You also can do a calc 10/3 %20.6f which returns a string with 6 digits and 20-6=14 spaces like ______________3.3333. So formatting of lists in shell scripts is real fun now.
Enjoy!
Hans
#!/usr/bin/perl
#
# The ultimate command line calculator :-^
# Usage calcme <string_to_calculate> [<output_format>]
#
# Input is a string like (10+3)/7 or "(10 + 3) / 7"
# Output is the calculated result of the string (sic!).
# Optional formatting can supplied as 2nd parameter.
if (@ARGV == 0 || @ARGV > 2)
{
die("Usage: $0 <\"formula_to_calculate\"> [<output_format>]\n");
}
$format = "";
$calcme = $ARGV[0];
(@ARGV == 2) && ($format = $ARGV[1]);
$output = eval($calcme);
if(@ARGV == 1)
{
print(STDOUT "$output\n");
}
else
{
printf(STDOUT "$format\n", $output);
}
exit(0);
-- Hans
Another Way to View Tarred FilesDate: Sat, 02 Aug 1997 02:18:07 +1000 (GST) From: Gerald J Arce [email protected]
In issue 19, I read a 2 cents tip regarding viewing a tarred file. I use less instead..
ex: tar tzf foo.tar.gz less foo.tar.gzLess typing (grin).
Script Ease Date: Wed, 6 Aug 1997 01:54:19 +0200 (GMT+0200) From: Trucza Csaba [email protected]
Hi all,
As a programmer-wannabe, I do a lot of typing. To ease at least the beginning of each source file (which is mainly the same: include-s, define-s, imports and stuff), I wrote a script to automatize this. For the quality of the script please read the notice at the end of my mail.
(file: se)
---------cut here---------------
#!/bin/sh
#
# source editor (se)
#
# usage: se <filename> <type>
#
# WARNINGS:
# 1. do not supply extension:
# se MyProg.java will make a MyProg.java.java!!!
#
# 2. manually create the
# SE_HOME_DIR,
# SE_HOME_DIR/temp,
# SE_HOME_DIR/templates
#
# man se:
#
# create two files for each type of the source you want to se.
# the script will copy the first file+filename+second file into a new
# file (you got it?:-)
#
# so: if you want java, create two files:
#
# templates/java.1:
#
# ---8<---
# public class
# --->8---
# (Do not put a newline at the end!)
#
# templates/java.2
#
# ---8<---
# {
# public static void main(String args[]){
# }
# }
# --->8---
#
# the script for se MyProg java (or jus se MyProg if the last time you
# used java as type) will create a new file called MyProg.java:
#
# public class MyProg
# {
# public static void main(String args[]){
# }
# }
#
# examine and modify at will
#
# author: Trucza Csaba [email protected]
#
# this script may be full of errors
#
SE_HOME_DIR=~/.source-editor
LAST_USED=$SE_HOME_DIR/last_used
if [ -f $LAST_USED ] ; then
SE_DEFAULT_TYPE=`cat $LAST_USED`
fi
case $# in
0)
echo "no parameter"
if [ -z $SE_DEFAULT_TYPE ] ; then
SE_DEFAULT_TYPE=java
fi
FILE_TYPE=$SE_DEFAULT_TYPE
FILENAME=~/.source-editor/temp/temp.$FILE_TYPE
;;
1)
echo "filename"
if [ -z $SE_DEFAULT_TYPE ] ; then
SE_DEFAULT_TYPE=java
fi
FILE_TYPE=$SE_DEFAULT_TYPE
FILENAME=$1.$FILE_TYPE
;;
2)
echo "name and type"
FILE_TYPE=$2
FILENAME=$1.$FILE_TYPE
;;
esac
echo "FILE_TYPE="$FILE_TYPE
echo "FILENAME="$FILENAME
if [ -f $FILENAME ]; then
echo file exists
else
build-template $FILE_TYPE $1
mv ~/.source-editor/templates/$FILE_TYPE.template $FILENAME
fi
echo $FILENAME
echo $FILE_TYPE > $LAST_USED
jstar -tab 4 $FILENAME
---------cut here---------------
The second script is a simple backup script, to back all the sources up and edit the tracking file.
(file: backup) ---------cut here--------------- #!/bin/sh # # kind of backup with kind of version control # usage: backup # # backs up the current directory (well not all of it, just your # programs) # # 1. creates a dir named backup (or whatever) # 2. in this directory will be a tracking file, a plain text file # in which you can write some comments every backup # 3. optionally in the file named filelist you can write the names of # the files you want to back up # 4. examine and modify at will # # author: Trucza Csaba [email protected] # # this script may be full of errors # # # where to back up # if [ -z $BACKUPDIR ] ; then BACKUPDIR=backup fi if [ ! -d $BACKUPDIR ] ; then mkdir $BACKUPDIR fi # # last version backed up # LAST_FILE=$BACKUPDIR/last if [ -f $LAST_FILE ] ; then VERSION=`cat <$LAST_FILE` else VERSION=0 fi let VERSION=$VERSION+1 # # prepare next backup directory # NEXT_DIR=$BACKUPDIR/ver.$VERSION mkdir $NEXT_DIR # # get files to back up # LIST_FILE=$BACKUPDIR/filelist if [ -f $LIST_FILE ] ; then cp `cat $LIST_FILE` $NEXT_DIR else # # if no filelist found, backup C and Java files # modify as you wish # cp *.c $NEXT_DIR >/dev/null 2>&1 cp *.h $NEXT_DIR >/dev/null 2>&1 cp *.java $NEXT_DIR >/dev/null 2>&1 fi # # update last # echo $VERSION >$LAST_FILE # # edit trackfile # TRACK=$BACKUPDIR/track echo >> $TRACK echo >> $TRACK echo "=====================================================================">> $TRACK date >> $TRACK echo "Version: "$VERSION >>$TRACK # # here use your favorite editor :) # jstar $TRACK ---------cut here---------------
They should be self-explanatory. but, These scripts should not be used for design or development of nuclear, chemical, biological, weapons or missile technology, or any other places where humans can be hurt
Syslog Thing
Date: Thu, 07 Aug 1997 15:00:29 -0700
From: Kent Friis [email protected]
In issue 20, I saw a 2c tip regarding syslog, Including changing the config file, and REBOOTING. Now wait a minute, I thought this was Linux. How can one get uptime's of 300+ days, if you need to reboot every time you change a config file.
The solution is simply to edit the config file, and kill -HUP (pid of syslogd).
You should NEVER need to reboot, except to install a new kernel.
Kent Friis.
Sorta E-mail-to-Fax...Well to-Printer
Date: Fri, 8 Aug 1997 20:04:30 +0500 (PKT)
From: Tee Emm [email protected]
Hello,
I can bet that many of you readers will try out this tip atleast for once. Here we go:
I work at an ISP here in Pakistan with 4 more shift engineers. We have offices in three different locations and, although email and talk are used very frequently, we sometime require ABSOLUTELY IMMEDIATE responce from the other office. Emails remain unchecked and talk request are sometimes ignored because the other party might be busy doing something else on a talk-disabled terminal. Well, you cannot ignore a Panasonic Dotmatrix printer printing out messages in your control center!
One of my so-to-say boss talked of having a utility which will poll a POP3 mailbox every few seconds and printing out any mail that might be in the box. He, being a visual basic guru, started writing a windows based application that would do the required. I, being a die hard Linux creature, started thinking how I can do the same on my dear Linux box. Well, it took me a day to ponder on this issue and when I clicked, it was just a breeze! Sixteen key strokes and I was ready with my system. I yelled 'Windoz Suxs, Linux Rules'!
I edited the /etc/aliases file and keyed in the following line:
urgent: "| lpr"saved, the file and did a 'newaliases' and bingo! Any mail sent to [email protected] was immediately printed on the screaming dot matrix printer. My boss was duly stunned!
(Note: You must have your 'lpr' command working before you can go ahead with this tip.)
Tariq Mustafa,
Setting Xterm Title to Current Process
Date: Tue, 12 Aug 1997 01:09:02 -0500 (CDT)
From: Rob Mayoff [email protected]
I saw this tip the Gazette: Hi, after searching (to no avail) for a way to display the currently executing process in the xterm on the xterm's title bar, I resorted to changing the source of bash2.0 to do what I wanted. from line 117 of eval.c in the source, add the lines marked with # (but don't include the #)
If you use ksh instead of bash, you can get the same effect without changing the source:
typeset -A Keytable
trap -- 'eval "${Keytable[${.sh.edchar}]}"' KEYBD
[[ "$TERM" == xterm ]] && \
Keytable[$'\r']=$'[[ -n ${.sh.edtext} ]] && print -n "\E]2;${.sh.edtext}\a"'
You can download ksh (the POSIX-compliant Korn shell) for free from http://www.research.att.com/orgs/ssr/book/reuse
CVS
Date: Thu, 14 Aug 1997 11:08:27 -0400
From: Paul Rensing [email protected]
Mario Storti wrote:
Using shar + RCS to Backup Set of Source Files
Hi, RCS (see rcs(1)) is a very useful tool that allows to store versions of a file by storing only the differences between successive versions. In this way I can make a large amounts of backups of my source files but with a negligible amount of storage. I use it all the time, even for TeX files!! However, when you are working with a set of source files (*.c, shell or Perl scripts, I work mainly with Fortran .f and Octave *.m files) what I want is to make backups of the whole set of files in such a way that you can recover the state of the whole package at a given time. I know that there is a script called rcsfreeze around, but I know that it has problems, for instance if you rename, delete or create new files, it is not guaranteed to recover the same state of the whole set.
I think a good way to handle this is by "upgrading" to CVS. CVS is a version control system built on top of RCS and was designed specifically to handle version control of large trees of files (the company who wrote it was a Sun VAR and handled the > 1000 files which they regularly received from Sun).
Once you have the project set up, you could simply do "cvs commit" from the top directory of a project, and CVS will check in all the changes to all the controlled files in the tree. If you are using this for "backup", you would only need to keep a copy of the CVS "repository".
Paul Rensing


|
Contents: |
 Linux® Trademark Resolution
Linux® Trademark Resolution
Ownership of Linux® Trademark Resolved
Monterey, California, August 20, 1997 - A long standing dispute over ownership of the Linux® operating system trademark has been resolved. As a result of litigation brought by a group of five Linux companies and individuals against William R. Della Croce, Jr. of Boston, Massachusetts, Della Croce has assigned ownership for the registered mark to Linux Torvalds, the original author of Linux, as part of the a settlement agreement.
The plaintiffs in the suit were Linus Torvalds; specialized Systems Systems Consultants, Inc. (the Linux Journal of Seattle; Yggdrasil computing, Inc. in San Jose; Linux International, Amherst, NH; and Work Group Solutions of Aurora, CO. Non-plaintiffs Red Hat Software, Inc., Metrolink Inc., and Digital Equipment Corporation supported the litigation and contributed to the cost of the litigation.
The five plaintiffs brought suit against Della Croce in the U.S. Trademark Trial and Appeals Board, in November 1996. Della Croce had obtained registration of the Linux mark in September 1995, which created a storm of protests by the Linux community, who felt the mark belonged to Torvalds or the Linux community and not to any individual. In an attempt to correct the situation, the plaintiffs retained the internationally known intellectual property law firm of Davis & Schroeder of Monterey, California, who handled the case on a greatly reduced fee bases, as a service to the Linux community.
The five plaintiffs, through their attorneys, announced that (1) the matter has been settled by the assignment of the mark to Linus Torvalds, on behalf of all Petitioners and Linux users, and the dismissal with prejudice of the pending PTO Cancellation Proceeding; and (2) that Respondent was reimbursed for his trademark filing fees and costs by Petitioners. The other terms of the Settlement Agreement are confidential.
All inquiries should be referred to Petitioners' law firm, Davis & Schroeder at 408-649-1122 or by email at [email protected]. A copy of the original Cancellation Petition filed in the TTAB, can be found at http://www.iplawyers/text/linux.htm.
Linux Journal 1996 Back Issue CD-ROM
Linux Journal announced the release and ship date of their 1996 back-issue CD-ROM. It will be available September 17, 1997. LJ's first back-issue CD-ROM will consist of twelve issuews of Linux Journal published during 1996. Features covered in 1996 include; systems administration, World Wide Web, back-ups, Linux distribution comparisons, software development, shell programming, getting new users started, graphics and several other topics.
An HTML interface will allow you to access the CD-ROM infromation using any World Wide Web browser. For those that don't have a World Wide Web browser, gzilla, has been included on the CD-ROM.
Linux Journal's 1996 back issues CD-ROM is $19.95 plus shipping and handling and can be ordered directly from Linux Journal.
For more information take a look at http://www.linuxjournal.com/.
Vi Mugs
You might be interested in the vi reference mugs found at http://www2.cic.net/~gpoulos/vimug_main.html. Check them out!
New Mailing List
Check out a new mailing list for Linux users to help each other with problems.. To subscribe send email to [email protected] with the following in the body: subscribe linuxlst
Linux Aptitude Test
There is a project which is trying to establish a quantitative measure to assist in determining a person's knowledge and general usefulness in Linux setup, configuration, and maintenance. The project is aiming to create a test that can be used to assess an employee's strenths and general understanding of Linux.
Take a look at http://www.icv.net/LAT
The Hawkeye Project
"Hawkeye" is the name of a new Linux Web server program, which has recently been released to the public. IT is an Internet/Intranet server suite, implementing Internet protocols for information interchange. A short list of the most important functions of Hawkeye:
Hawkeye is running under the LINUX operating system and requires the Linux SQL database MySQL http://www.tcs.se. Hardware requirements are much like what you would need to build a normal Linux system. For optimal performance, we recommend a Pentium machine withat least 16 Megabytes of RAM. Hawkeye itself uses very little Harddisk space, so the size depends mainly on your site. Check it out on the Hawkeye Web Home Site
LinkScan 3.1 Released
Electronic Software Publishing Corporation introduced a number of new features in LinkScan version 3.1. There is added ability to check hyperlinks that are embedded within Adobe Acrobat PDF files and enhanced TapMap features such as...
Free evaluation copies of LinkScan 3.0 may be downloaded from the company's website at: http://www.elsop.com/linkscan
 The Answer Guy
The Answer Guy
 Linux Control Panel
Linux Control Panel
I have recently installed RedHat Linux ver 4.2 on my pc . My problem is that I cannot get the control-panel to work when I run startx or XDM . The panel comes up but I am unable to activiate any buttons in control-panel . I don't know what I did wrong or what to check ! Please help...
 Are you running it as root?
Are there any interesting error messages in /var/log/messages?
Are there any interesteing error messages back on the text
console from which you ran "startx" (you can switch out
of XFree86 with {Ctrl}+{Alt}+{Fx} -- where {Fx} is the
function key that corresponds to any of you other virtual
consoles). Are you sure you installed the Python and
related libraries (last I heard all of the Red Hat GUI
control panel stuff is written in Python).
Are you running it as root?
Are there any interesting error messages in /var/log/messages?
Are there any interesteing error messages back on the text
console from which you ran "startx" (you can switch out
of XFree86 with {Ctrl}+{Alt}+{Fx} -- where {Fx} is the
function key that corresponds to any of you other virtual
consoles). Are you sure you installed the Python and
related libraries (last I heard all of the Red Hat GUI
control panel stuff is written in Python).
As I've said several times -- I'm not a Red Hat specialist (although that is what I'm running here at the moment) and I barely use X (since I vastly prefer old fashion text mode).
Have they ever gotten a support line running that can answer questions that are specific to their code? (Hey! I wouldn't even object to a paid support line -- if it was good).
Thank you for responding to my question I will look into the areas
you suggested . However I have one other question that is how would I
activate my modem from a Linux command line? I thought I needed the
xwindow to do that in the first place.
One of the virtues of Unix is that you don't need X Windows
to do anything except run X applications -- there are other
ways to access graphics (SVGALib, MGR) use your mouse (GPM)
do cut and paste (GPM/select, 'screen'), provide task/session
switching (virtual consoles, and 'screen'), do screen management
('splitvt', emacs) etc.
In answer to your question regarding modems: There are a number of programs that are included with the typical Linux distribution that may use your modem:
pppd is the PPP daemon -- it usually uses the 'chat' command to talk to the modem.
minicom is a vaguely Telix like ncurses terminal emulation package (Telix is a popular shareware MS-DOS program). It provides a fullscreen, color interface.
'cu' is a "call utility" usually associated with UUCP. It uses the UUCP configuration files for information about your modem -- if you have those configured. It's a very limited communications package -- that's only virtue is that it is small.
UUCP is a suite of programs -- of which the uucico program actually talks to the modem. You almost certainly are not planning on using this. However UUCP was (and still is) used as a mail, file, and netnews transport protocol for years before TCP/IP existed. I still use it for my mail.
C-Kermit is a communications package from Columbia University. You can fetch it freely -- but it can't be included with Linux (or other) CD-ROM collections of software due to it's licensing model. If you decide you like it you should buy a copy of the C-Kermit book by Frank da Cruz (the program's principal architect and head of the project since it's foundation).
C-Kermit is also a scripting language and can be used as a telnet or rlogin client, and Kermit is a file transfer protocol which can be used by C-Kermit over any communications channel that it can establish. I wrote an article for SysAdmin Magazine on the subject just a couple of months ago.
There are other program that access your modem if you want to use them, There's a SLIP package which usually controls the modem via 'dip' -- there's a variety of different "getty" implementations which "Get a tty" (terminal) so that you can log in from a terminal, or another system running a terminal package.
I use mgetty which not only allows incoming dial-up data connections but adds support for FAX and even voice/DTMF with some modems. That package also includes "sendfax" -- a program for outgoing faxes. efax is another package for support FAXes under Linux.
Judging from your earlier question regarding the Red Hat Control Panel I suspect that you're just interested in configuring your system for PPP access to your Internet service provider (ISP). There is a script floating around (on http://sunsite.unc.edu somewhere) called 'pppsetup'. I think this will allow you to setup your PPP configuration from a text console (I used plain old 'vi' and made my own configuration files -- so I've never used this -- though I've seen it recommended many times).
There are several HOW-TO's on configuring PPP (and SLIP) which can be found at http://sunsite.unc.edu/LDP/HOWTO Look for the ones that refer to "PPP" and "ISP."
Hope all of that helps.
-- Jim
Linux Command Line Arguments
From: Ronald B. Simon [email protected]
Where can I find a list of the linux boot command line arguments? e-mail addresses:
Look in the following HOW-TO document:
BootPrompt HOWTO
http://sunsite.unc.edu/LDP/HOWTO/BootPrompt-HOWTO.html
-- Jim
More Random Crashes
Date: Fri, 01 Aug 1997 14:40:06 -0700
From: sloth [email protected]
Hi, I wrote to you a while ago with a problem regarding random crashes while installing Linux... I recently tried again, with exactly the same hardware but a different hard disk and the whole thing worked fine. unfortunately, the hdd i used was only and 80mb conner :). The hard disk i want to use is a 2.1 gb Quantum Fireball. When I try on this hard disk the computer locks up at a different place each time during the installation ( but only when it is decompressing the files). I have an IDE Hard disk controller.
h/w list:
any help would be much appreciated.
cheers, sloth...
This new information about your situation suggests two
possibilities:
1) Your HD is bad -- possibly it has some bad sectors that the drive electronics haven't mapped out, or possibly it's something more subtle.
2) Your controller (IDE) is incompatible with your HD and/or the combination of your HD and CD drive.
Some notes:
Any IDE drive that's over 540Mb requires an EIDE (enhanced IDE) controller/BIOS. There have been cases where specific IDE devices weren't compatible with one another -- where a particular combination of devices couldn't share the same IDE channel.
So, try getting a new EIDE controller and disabling the interface on the motherboard (or configuring the new on as a "secondary" IDE channel. Try running the two devices on the new EIDE controller if you can get it installed as the primary (but don't blindly trust the motherboard documentation -- I've heard that some of the "disable me" settings on some boards just don't work). Then try running the CD-ROM drive and the hard disk on separate channels (controllers).
If you can get a copy of Spinrite or the Norton Utilities for DOS then you might install a small DOS partition and run that on your Fireball. It might be able to map out any bad sectors.
If you get a new controller (which will be less expensive then buying either of the software packages I just mentioned) I'd try a a QuickPath Portfolio or a GSI brand multi-funtion card with 4 high speed (16550 UART) serial ports. The QuickPath is an ISA card (rather than taking up one of your PCI slots for a set of relatively slow interfaces) and is what I'm using in a couple of my machines here. It combines floppy, four serial, two parallel, two IDE channels and a game port (for 13 devices in all).
Hope that helps. Unfortunately the diversity and cheapness of PC hardware results in a diversity of inexplicable incompatibilities and a common "cheapness" in quality that's imposed by the competition. So, as much as I hate to recommend "black magic" experiments in new hardware -- it's frequently the most effective approach.
-- Jim
More on Disk Defrag
Date: Mon, 4 Aug 1997 20:27:11 +0200
From: Markus Enzenberger [email protected]
...them in any Linux books that I have consulted. Is disk degragmentation not needed in maintaining a Linux file system?
No, disk fragmentaion is a particular problem of the DOS FAT file system
and its descendants. You can see the fragmentation status of one your
partitions by running the e2fsck file system check program as root
on an unmounted partition. It is run every boot time too. It will report
the amount of non-contiguous files.
- Markus
X-Windows is Crashing
Date: Sun, 13 Jul 1997 19:34:12 -0700
From: Gerramie Dinsel[email protected]
Hello. I am searching all over for an answer or a pointer to this problem:
I upgraded my memory from 18 megs to 48. Now, X-Windows crashes on me when I load FVWM2.. Odd, because XDM loads fine and will sit there, waiting, without crashing for as long as you want. Also, console mode works wonderfully...
Can you offer any help? Gerramie Dinsel
The first guess might be that the new memory is bad --
and that you normal (console) usage -- and the overhead of
xdm just doesn't "land" on the bad chips.
One way to test this would be to do something from console mode that will use *a lot* of memory. make's -j switch (to parallelize as many gcc processes as memory allows) is a good way to test for this sort of thing. Just make a new kernel (no need to even to an install of it -- just the make is fine).
If that runs O.K. than we have linked the problem X -- possibly to any graphical use of the card beyond xdm's. So we try to run X with no window manager and a minimal configuration file (no setting of special root images like xli, xloadimage, or xsetroot, no -16bpp or any of that).
It could be that your video card uses a region of address space (a video frame buffer). Look carefully in the configuration settings, or call the manufacturer's tech support. That's the most likely problem.
If you have access to another, simpler video card -- try swapping it in and seeing if that helps. If it does than you need to reconfigure that video card or use one that's better behaved.
If that doesn't help then it's just anyone's guess what's happening. Try rearranging the adapters in your card cage -- it may be that the video card is emanating some noise or crosstalk that's affecting your RAM. Re-arranging adapters used to be a time honored sport among PC technicians. I think it's more rare in the PCI era -- but you don't even mention what sort of bus your using -- and I have no information about your hardware. Besides -- it can't hurt.
If it still doesn't work try switching to 32Mb. This might be some weird chipset bug on your amount of RAM. More systems work with 16 or 32Mb of RAM than with 24 or 48Mb.
There are a plethora of parameters you can pass to the kernel for excluding specific memory address ranges from its use. They might help -- but I'd hate to have to experiment with them.
-- Jim
Lynx and Frames
Date: Tue, 05 Aug 1997 02:48:26 -0700
From: Scott [email protected]
Hey Jim, Caught this quote in your article:
(Warning for Lynx users -- both of these sites use frames and neither bothers to put real content in the "noframes" section -- Yech!)
Current versions of lynx support frames and tables in a fairly nice and elegant fashion. They even handle cookies.
Check out http://lynx.browser.org
Just thought you should know. Sure, I use Netscape for some of my browsing and I hope to begin using Mnemonic soon. But for really fast, heavy-content oriented browsing, lynx on the console or in a color-xterm does the trick.
Scott
Oh, I know that Lynx 2.7.1 can handle frames, by simply
showing you a list of the available frames as a set of hot
points at the top of the rendered page. I use Lynx for almost
all of my web browsing.
The problem is that the HTML editors used by many sites don't put meaningful names on the frames so you get a list of: frame01.html, frame02.html, etc. instead of something like: navigation.html, main.html, toolbar.html etc.
It's as irritating as those sites that use large tableaus of image icons with no Alt="" attributes or imagemaps that with no sane information in the .map file. (The current Lynx can also handle most types of image maps.
-- Jim
More on ftpd
Date: Tue, 05 Aug 1997 01:59:18 -0700
From: Benjamin Peikes [email protected]
Jim,
I am currently trying to set up some user accounts on our webserver so that other people working on their sites can ftp their files up and down easily. I am using wu.ftpd and have set up the line
guestgroup ftponlyin /etc/ftpaccess. I have also added the group into /etc/group and added the users name to the group. The problems is that everything seems to work correctly except that ls and dir return nothing during an ftp session.
I'm so close that it's driving me nuts. The main problem arises when people need to transfer entire directories. Most of them are using GUI driven ftp clients and the lack of directory listings kill those clients. I know there must be a simple solution. Any help would be great.
Ben
You're probably having problems with the shared libraries
or devices that are typically required by the ls command.
Some version of ls require that you have a /dev/null and/or
a /dev/tcp in order to work properly. Most versions of ls
require some shared libraries and all of them require the
existence of some of /etc/passwd and /etc/group files (even
with completely fictional data in them) in order to resolve
UID numbers into symbolic ownership information to display in
long listings.
For real information about setting up wu-ftpd on any platform look at the following resources: http://www.landfield.com/wu-ftpd/ http://www.cetis.hvu.nl/~koos/we-ftpd-faq.html (Or, send mail with subject of "send faq" no quotes, body ignored).
... and information about the guestgroups feature in particular can be found at: http://www.landfield.com/wu-rtpd/guest-howto.html
... or ftp://ftp/fni/com/pub/wu-ftpd/guest-howto
A document describing virtual ftp servers: http://www.westnet.com/providers/multi-wu-ftpd.txt
Ftpaccess on virtual ftp servers ftp://ftp.meme.com/pub/software/wu-ftpd-2.4.2/README.ALT.FTPACCESS
Hope that covers it.
-- Jim
DNS Problem
Date: Mon, 04 Aug 1997 18:31:36 -0700
From: Dr Ceezaer [email protected]
(Ping doesn't work -- but /etc/resolv.conf and /etc/hosts.conf are correct and nslookup works).
It used to work before I upgraded my library files (/lib and /usr/lib) so I don't think there is an error in /et/resolv.cfg
Well... I've solved the problem. First I re-installed Linux on a small 120 MB harddisk. By comparing all relevant directories I found that I had a file called libc.so.5 (no symlink) in /usr/X11R6/lib plus the normal one in /lib. By removing the file /usr/X11R6/lib/libc.so.5 it all works again :)
Ahh the mysteries of the shared libraries. I've always
wondered how the dynamic loading code searches for these .so
(shared object) files. However I've never wondered enough to
leave stray copies of them laying around.
Well... I would need such a HOWTO, I didn't even got chroot to run...
The only real trick is to do a 'cd' before trying to execute
the command -- otherwise your process is very confused becuase
it can't access its current working directory (cwd).
The other problem is that your target program must be contained in the chroot tree with any shared libraries and usually it will need a set of /etc/ files including the termcap and maybe a set of /usr/lib/terminfo files.
-- Jim
Sendmail
Date:Sun, 10 aug 1997 14:4457 -0700
From: Stephen P. Smith [email protected]
When I send mail (using the mail program) to someone my reply to address is wrong. What sendmail is sending is [email protected] What I want is [email protected] What do I need to change to fix this
Stephen Smith
You use the "masquerade" feature in your local sendmail
configuration. I recommend that you use the m4 macro
package to reate a new sendmail configuration.
First copy the old configuration. I like to use RCS -- the revision control system to track changes to my configuration files. Here's how you'd do that:
(As root)
# cd /etc # mkdir RCS (unless you already have one) # ci sendmail.cf (checks the cf file into the RCS directory) # co -l sendmail.cf (checks it back out, locked for editing)
Now you want to create a sendmail "mc" file. This is a file that uses sendmail specific macros -- which is then processed by the m4 program to generate the full sendmail.cf. A typical sendmail.cf is over a 1000 lines long -- a typical "mc" file is less than 20.
Under my Red Hat installation the sample "mc" files are located in /usr/lib/sendmail-cf/cf/. You can put yours there, or you might use /usr/local/lib/sendmail (and perhaps add a symlink under the other path). This helps maintain the separation between your local changes and the distribution's files "as shipped."
I name my "mc" files after my hostnames -- so mine is "antares.mc." It looks like this:
divert(-1) include(`../m4/cf.m4') VERSIONID(`@(#)antares.uucp.mc .9 (JTD) 8/11/95') OSTYPE(`linux') FEATURE(nodns) FEATURE(nocanonify) FEATURE(mailertable) FEATURE(local_procmail) FEATURE(allmasquerade) FEATURE(always_add_domain) FEATURE(masquerade_envelope) MAILER(local) MAILER(smtp) MAILER(uucp) MASQUERADE_AS(starshine.org) SITECONFIG(uucp.antares, starshine.org, U) define(`UUCP_RELAY', a2i) define(`UUCPNAME', starshine) define(`UUCPNODES', a2i) define(`RELAY_HOST', a2i) define(`RELAY_MAILER',uucp) define(`SMART_HOST', uucp-dom:mailer) define(`PSEUDONYMS', starshine|antares|antares.starshine.org|starshine.org) undefine(`BITNET_RELAY')
I've seen some of these that end each line with a 'dnl' -- which is a macro to "do newline" -- I don't bother with that.
You'll want to ignore all the UUCP references and my SITECONFIG line (mine is also a UUCP reference -- so yours will be different -- preserve whatever is in the samples that mathc your current configuration).
What your interested in here is the various "masquerade" lines. Now you'd just 'cd' to the directory where you've created this "mc" file and issue a command like:
m4 < $MYFILE > /etc/sendmail.cf
(where you replace $MYFILE with whatever you named your "mc" file, of course).
It's also possible to to simply add a line like:
DMisp.com
... directly to your /etc/sendmail.cf. DM "defines masquerading" to be for "isp.com" (from your earlier example). This is easier, on the one hand -- but learning the m4 configuration method will serve you well if you ever have to do upgrades to your sendmail -- and it's a valuable skill if you ever have to administer Unix systems as (or as part of) your work.
There are a variety of HOWTO's on configuring your mail to work well with your ISP. I don't have my PPP connection up at the moment -- but you should search the SSC web site (http://www.ssc.com) for the the HOWTO archive and look for the strings "ISP" and "mail."
-- Jim
Linux PPP Server
Date: Sun, 10 Aug 1997 05:34:45 -0700
From: [email protected]
I have a Linux PPP server but I can not get my Windows95 client to do the "automatic" login. Sure, I can get it all to work if I check "bring up terminal window after connecting".
All I have is the login: prompt, followed by the Password: prompt then right into PPP.
What gives ?
TIA
-Rob
Here's a URL that talks about getting Linux
mgetty to work with Microsoft's infamous "AutoPPP":
ISP Resources - mgetty info(AutoPPP)
For more general information about mgetty look at: Mgetty + Sendfax Documentation Centre
-- Jim
Linux/Unix Emulator
Date: Sun, 10 Aug 1997 05:30:18 -0700
From: Jun Liu [email protected]
Hi, Dear James,
First I'd like express my gratitude for your great work on the Linux Gazette. But for the Linux/Unix Emulator, I think you're somehow wrong. Actually there do exist at least one such product as far as I know. When I was staying in Japan, I've learned there're quite some people there use a software called BOW (namely BSD on Windows ), which is a BSD emulator for Windows. Check out http://www.ascii.co.jp/superascii/bow if you do know Japanese. In short, this is a BSD kernel emulator for 4.4BSD-Lite based BSD Unix program. It's said most BSD binaries (x86 certainly,character mode applications only, no X, no debuggers like gdb) can be run unmodified.
Actually, there has been quite a bit of work on supporting
Unix under NT. Cygnus Support (http://www.cygnus.com) has
made quite a bit of progress with their
GNU-Win32
Project
A couple of other sources worth noting are: OpenNT 2.0 Server Data Sheet UNIX to NT Resource Center
There was also a paper presented at the Anaheim USENIX
conference this year:
The advantages are, you have the rich development environment from Unix, and the nice( ? ) UI from Windows as well as lots of Windows applications around all at the same time. It's said BOW Version 1.5 which is Windows95 compatible, is already published last year in May as a book and available in Japanese bookstores, priced at 9,800 yen with one floppy disk and one CD-ROM.
Hope this can be helpful.
Best regards.
Stefan
Again, in the article to which you refer I was asking
what the original person was asking for. Many Unix packages
have been ported to NT, Windows '95, and DOS (emacs, perl,
awk, most of the simple commands like grep, cp, find, and
a couple of shells: Korn, bash) -- and it would certainly be
possible to host some binaries under (ELF, iBCS).
At what point to NT become Unix?
-- Jim
LILO Concerns
Date: Sun, 10 Aug 1997 03:50:35 -0700
From: Tibs [email protected]
I have been looking all over for an answer to my linux question...nobody seems able to help so I thought I'd ask you (liked the LG web stuff very much). I am about to take the plunge and install linux but I am concerned about how LILO will work on my system. I have two IDE drives on my system. The first is 1 gig and I have DOS, Win95, etc. on it and that's what I boot to. The second is divided into two 1.5 gig partitions, and 1 500 meg partition. I planned on putting linux on that last 500 meg partition.
First: you'll want to learn how to use paragraphs.
Break your question down into short steps so we can
read it (particularly when we're doing the reading at
3:30 in the morning after hacking all day)
.... The problem is that in order for my computer to
recognize the full 3.5 gig capacity of the second hard drive, the hard
drive installation floppy (it's a Maxtor) installed something called
EZ-BIOS. So booting to DOS or Win95 now works and my BIOS recognizes all
3.5 gigs of the space. When I boot to a floppy I have to use the EZ-BIOS
"boot to a:" option otherwise I can only access the first partition on
the second drive. So when I install linux and add LILO, will LILO start
doing stuff after the EZ-BIOS stuff loads? If so then it is not a
problem but if LILO starts before EZ-BIOS does it's thing, then I don't
think I'll be able to access my 500 meg partition. And since that's
wherelinux would be, that would be a bit of a problem.
You're using an alternative master boot program which
will be incompatible with any other boot software.
You should use LOADLIN and forget all about LILO.
I've written about LOADLIN several times in this column -- so please look back through some of the pack issues for details.
So I guess my question would be:
1. do you know anything about this EZ-BIOS stuff and it's compatibility
with linux (the Maxtor people aren't helping with linux questions)
The EZ-BIOS and the old Ontrack Disk Manager and similar
drivers were originally created to allow DOS to see larger
partitions (which they did by hooking into the BIOS Int 13H
disk access routines before DOS was loaded -- by replacing the
MBR). They have always been a bad idea.
Now that DOS supports partitions larger than 32Mb these programs have a different purpose -- to allow older systems to see IDE drives that are larger than 512Mb. The BIOS interface only supports a maximum of 1024 cylinders of up to 64 sectors each. A typical drive is less than 16 heads. This "geometry" gives a maximum of about 528Mb. It's possible to "lie" to some BIOS' and double the number of heads -- or even go up do 255 "virtual heads" -- the drive electronics will simply translate for you.
Essentially this is how SCSI and EIDE drives give you access to larger disks (up to about 9Gb).
Your other alternative is to get an EIDE controller and get rid of the non-standard software (sofware which isn't supported under OS that I know of, Linux, any Unix, FreeBSD, NT, OS/2 or anything other than DOS).
2. is there some workaround that would still let me use linux if EZ-BIOS
would be a problem (like using a boot floppy everytime I wanted to use
linux, or something like that)
You can probably just use LOADLIN. However you might have to
cook up some weird boot time parameters (you can store them
in the bathc file that invokes LOADLIN) to tell the kernel what
the drive geometry really is -- so it doesn't step on anything.
Here are the two HOWTO documents you want to read:
-- Jim
Crypt
Date: Fri, 08 Aug 1997 20:47:11 -0700
From: David Saccon, [email protected]
Hi; I'm a Linux enthusiast bla bla bla, compliments for the good work, etc etc.
Well, charmed I'm sure!
I don't know if an e-mail to this address is the right way to
ask you a question.
It isn't really -- but most of the readers of Linux
Gazette's "The Answer Guy" column haven't see the "tag@"
address that I currently prefer.
Please feel free to get rid of this mail if it bugs you.
Anyway, my question is: where can I find an implementation of
the fine tool "crypt" for Linux ?
You know, "crypt <myfile >myfile.x password", and back to the
clear text the same way.
I'm not sure that the traditional Unix 'crypt' command is
all that "fine." I'd suggest that you obtain a copy of
PGP from one of the international sites that carry it.
(Please don't obtain it from any of my "free" fellow U.S. citizens -- since it would be illegal for them to exercise this particular form of free speech at this time. I'd like to apologize for the ludicrous attitude my government takes with regards to cryptographic software -- feel free to refer to the "Electronic Freedom Frontier" (http://www.eff.org) for more information about that).
I haunted the internet for days but couldn't find it.
I also tried something like this:
include "stdio.h"
include "unistd.h"
void main(int argc, char ** argv )
{
puts(crypt(argv[1], argv[2]))
}
but it doesn't work the same way.
Help!
Thank you
Davide Saccon
There is a library function named "crypt" which is technically
a "hash" rather than a cryptographic function -- it's used to
compute the hash of a password for comparison to that which is
stored in the second field each entry in the /etc/passwd file.
I've heard that the program named 'crypt' varies from one Unix implementation to another. I think its currently not included in many Linux distributions to the export (U.S. ITAR and related) restrictions to which I alluded earlier. Since many of the companies that produce these distributions are U.S. they would have to ensure that their products were for "domestic use" only if they were to include this on their CD's and in their FTP sites.
Here are a few sites I picked off of Yahoo! International PGP FAQ Guida Pratica a PGP Guida Pratica a PGP PGP User's Guide (in Italian -- 250K) The Crypto Chamber -- Italian Cryptographer's WorkBench.
There are other strong cryptographic products available internationally for other purposes. I think the new Linux "TCFS" (transparent cryptographic filesystem) is being done in Italy. TCFS is apparently similar to Matt Blaze's research on CFS -- it allows a Linux admin to create filesystems that are encrypted in such a away that users can have confidence that no other user access their files. Given its design is should be difficult even for the root user to compromise the cryptographic integrity of any local user -- and it should be impractical for remote systems.
Here's some more links for that: Transparent Cryptographic File System Project Page TCFS TCFA FAQ v1.7.7
Come to think of it STEL (a secure telnet) was also done in Italy. Seems that a lot of work on cryptography is coming out of your country. Obviously your government hasn't been interferring in this work. If you'd like to look at the sources for STEL I'd FTP over to ftp://idea.sec.dsi.unimi.it/cert-it/
Another set of useful cryptographic resources are in Eric A. Young's free implementation of Netscape's SSL (secure sockets layer) specification and a set of related applications (like ssltelnet and sslftp): SSLeay: SSLeay and SSLapps FAQ SSLeay: SSLeayand SSLapps FAQ
(This set of pages is an excellent resource for anyone that wants to learn anything about SSL).
Eric's work was instrumental in the development of the Stronghold web server by C2 Software Inc. (http://www.c2.net) (I recently published an interview with C2's founder, Sameer Parekh, in Linux Journal, if your interested).
And, of course, no discussion of Internet cryptography tools would be complete without a mention of Tatu Ylongen's SSH ssh (Secure Shell) ssh FAQ
-- Jim
Apache 1.2.1
Date: Mon, 11 Aug 1997 13:53:14 -0700
From: Alf Stockton [email protected]
I am playing with Apache 1.2.1 and have it running well except that it
won't run cgi scripts.
If I give the full path in the command line of the browser the CGIs run
fine but the server cannot/does not run these CGIs when I expect it to.
Where can I turn for help? The Apache team don't appear too interested.
I suspect that one of my config files is wrong but don't know enough to
tell which.
I wouldn't necessarily say that the Apache team isn't
"interested." However, they far more interested in
providing the software than in answering questions about
it.
It sounds like you don't have your "ScriptAlias" set up correctly -- or you're trying to access a CGI script that isn't stored in one of the proper "ScriptAlias" directories.
Here are links to the relevant documentation pages at the Apache site (http://www.apache.org):
Apache: Configuration: ScriptAlias http://www.apache.org/docs/mod/mod_alias.html#scriptalias
Apache: FAQ: How do I enable CGI execution in directories other than the ScriptAlias? http://www.apache.org/docs/misc/FAQ.html#CGIoutsideScriptAlias
Another possibility is that you have built it with no CGI support. Apache has many compile-time configuration options -- include a large list of "modules" that can ben enabled or disabled. However I'm sure that it would take some work to build Apache with no CGI support -- so I think this possibility is remote.
-- Jim
Red Hat Questions
From: Brent Johnson [email protected]
So are you the answer guy and can you answer a very important question for me?
I appear to have been dubbed "The Answer Guy" (it wasn't
a self-appointment -- but I did volunteer for it).
I can certainly answer any question. Answering it correctly and usefully are not as sure a bet -- but I'll try.
I first heard about RedHat's Linux distribution about a year ago and there
was no way Slackware could compete to the easy installation procedure,
RPMS, and other great features included in RedHat.
But, ever since I moved to RedHat Ive had a terrible gcc compiler problem. This has happened to me on two different machines... on the first Id assumed it was some memory problem (as in hardware), but now Im on a totally different machine that has (or shouldnt have) any memory problem.
Everytime I try and compile anything (Apache 1.2.1 for example)... it gets to about the 3rd or 4th .c file, and it bombs out with the following error:
gcc -c -Iregex -O2 -DLINUX=2 util_date.c gcc -c -Iregex -O2 -DLINUX=2 util_snprintf.c gcc: Internal compiler error: program cc1 got fatal signal 11 make: *** [util_snprintf.o] Error 1
It happens at different times on different .c files when compiling different things. Any help would be greatly appreciated... a Unix system with a defective compiler or defective hardware is almost useless!
- Brent
I notice that you haven't told me *which version* of Red Hat
you're working with. However I've used 3.03, 4.0, 4.1, and
4.2 -- and I think I remember playing with an earlier one before
3.03 and I never saw this behavior from gcc.
I did get it from my original copy of minicom anytime I was running in an extended video mode and trying to use the dialer (and not when issuing the same dialing function as a direct ATDT command from the terminal window). In this case I suspect there was a bug in the ncurses calls being made by minicom. In any event I switched to CKermit and forgot all about it.
In your case the signal 11 (SEGV) is probably not caused by curses/ncurses calls.
Do you have a swap partition or file? If so, have you tried disabling it (possibly creating a new one temporarily)? If you have a defect on the disk you could get a SEGV from some piece of data/code that gets swapped out, read back in (with errors) and subsequently used by the running process.
If you don't have a swap partition or file you might just be running out of RAM completely. gcc does use up quite a bit of memory -- so I'd suggest at least 32Mb virtual memory (RAM + swap) available when running it (you could certainly ask the FSF for more specific recommendations -- this is just my unsubstantiated and untested suggestion).
When you installed, did you let Red Hat's install routine perform thorough block checking while it was making filesystems? If not, try re-installing and enabling that (in case you hit some bad spots on your disk and you have corrupted gcc binaries).
This is extremely unlikely to be related to your distribution, but you could try installing Slackware to see if its gcc works on this system -- or you could try booting up in single user mode and just run a few test "make's" from a simple shell line (no emacs M-x shell mode, no X Windows, no "integrated dev. environment" nothing else running).
If you still get SEGV's then, you want to find some other sort of memory intensive program to run as a test -- to see what else will die. It may be worth extracting the RAM and taking it to a good hardware tester -- and/or removing any ethernet cards or unecessary adapters for other tests.
These sorts of things can be very frustrating to track down regardless of OS. If you have a copy of DOS and an old copy of Norton Utilities (version 8 or later) you could boot that up and run NDIAGS.EXE. There are several other diagnostics packages that were available before it -- but NU is still my personal favorite untill the Linux crowd does up a suite of them. Unfortunately the results of any software diagnostics package aren't definitive -- they can detect trouble -- but they can't "prove" that there isn't any hardware problem.
I suppose, for some systems, particularly some 386's and 386SX's, you might also try twiddling the CMOS "wait states" settings. Those used to make a difference -- particularly with earlier generations of "3-chip" SIMM's. Apparently in the early attempts to use SIMM's with three chips (two four bit chips and a parity bit chip) there were some slight timing differences between the "signal settling" characteristics -- so the parity bit wouldn't "settle" before the system was trying to read the memory. This resulted in parity errors if the systems were set for "zero wait states" -- and was generally solved by changing the CMOS settings.
(I've never heard of a Pentium system or any system using 72-pin SIMM's having these problems -- but that doesn't mean it's not worth looking in your "advanced" CMOS and trying some experiments therein).
I hope some of this helps.
-- Jim
PPP and Internet MCI
From: Demosthenes [email protected]
Subject: Re: PPP and InternetMCI
Hey there, I've been reading through your column from August in the Linux Gazette, and ran across the gentleman's question regarding GTE's internet services.
I'm trying to switch over to MCI from a local ISP, and I'm having some of the oddest connection problems. I use PAP currently with my local ISP, and MCI is supposed to use PAP/CHAP (one, the other, or both :P). I beleive i have everything setup properly, as I don't get any rejections from PAP/CHAP, but after a few seconds of modem activity with the server, MCI just hangs up. I did misspell something before, and got a PAP rejection, and I've got full debugging logs regarding the connection, but I can't make much sense of them. I know the server isn't asking for MS-CHAP (chap 80, vs chap 05). It looks like it dies during the configuration. I'm not sure.
Do you have any information regarding connecting to InternetMCI via Linux? MCI tech support is clueless, and I can't even get someone that knows how their own software works on the phone.
Any help would be highly appreciated, and I'd be more than glad to share my debugging logs if you think they will help.
Thanks again!
Russell Adams
My first impulse is to say "vote with your feet."
Fire off a polite, assertive, note to their VP of Customer
Service and go find a Linux/Unix friendly ISP with quality
tech support (and maybe spend a little more in the process).
My provider isn't the cheapest -- and isn't even the friendliest -- but they understand Unix and they provide quality service (refusing to structure their rates to "compete" with an unreasonable "quality of service" -- i.e. I get few busy signals).
That bit of non-technical advice aside I'd ask: What are your MTU and related parameters?
You could send the logging output -- but it would probably be as incomprehensible to me as it is to you. I've never set up a PAP/CHAP system (yet). However I'll look at them and suggest some experiments.
-- Jim
Enabling Automounter on a Linux Notebook
From: Dennis Dai [email protected]
Hi, Jim
I think I need to ask you for help. My problem is:
Originally I have a 1.6G HD. Last month I bought a new one (3.2G) in order to accommodate linux and NT. I placed the swap partition in the very last part of the new harddisk (it seems that this is a bad idea, isn't it?) which is hdc8 and initialized it without problem. After a while, I made a new NTFS partition for NT which resides in front of the swap partition (I installed NT system on one of my original HD's partition which is hda7), then I moved some of my data on the new NTFS partition. But after I booted up to linux, I realized that the swap partition didn't initialized properly, so I issue a command like this:
mkswap /dev/hdc8
And this was how I screwed up things. Actually the new NTFS partition became hdc8, and the original swap partition became hdc9. Now I can't access the new NTFS partition from NT!
Immediately after I issued that command, I realized that I made a big mistake so I issued a "free" command and it showed that the swap partition (which is my NTFS partition) was not used.
So I think I still have hope to retrieve the data on my NTFS partition. I know they are still there, just I can't get them out.
I posted this to linux newsgroups, and received some kind response that suggested me to use linux fdisk to change the partition type to NT one. But I did check that, it is still NTFS (actually HPFS under linux fdisk). Others suggested me to zero out the first 512 byte of that partition as part of the recovery, but since I am not quite familiar with that I didn't dare to do that.
So I hope you can get me out of the hole. Thanks in advance.
Well, I haven't done regular data recovery for a few
years (since I left Symantec' Peter Norton Tech Support
Department). It's not something that I can do via e-mail
(or for free) -- and I don't know diddly about the internals
of NTFS (or HPFS or ext2fs for that matter).
You best bet, of course, is to have recent backups from which you can recover. I don't know why they were suggesting that you blast the boot record (the first 512 bytes of a partition is the "logical boot record" or "superblock" while the first 512 bytes of a drive is the "master boot record" or MBR). Perhaps they believe that NT will be able to recover from this. If I was to do anything with the LBR I'd go to a different machine, create a new NTFS partition that was indentical in size and configuration to the one you think you've damaged, and use a disk editor (or a Linux dd command) to cut and paste that from the other machine onto the allegedly damaged partition.
Before doing much of that I'd suggest do a dump to tape of the entire raw device (using 'dd'). This may allow you to return to the current state of brokenness after you've made unsuccessful attempts at repair.
I don't recommend these procedures (disk surgery) unless the data on that drive is very important to you (and otherwise unreproducable) or you really like playing with hex editors.
If it's of considerable financial value to you -- I'd suggested making a dump tape, extracting the drive from the system and sending it to a data recovery specialist.
-- Jim
X Locks Monitor
From: Gord Urquhart [email protected]
I have found when playing with my Xconfig I could get my monitor (MAG15) to go into power saving state (with a resulting black monitor) when I changed the pre and post sections of the horizontal scan line timings (I can't remember the proper names of these), to certain values.
gord u.
... and? ...
You can also cause a monitor to permanently damage itself if you play with those long (wrong) enough. This is well known and noted in the XFree86 configuration file.
So, what's the point of this message? Or is it just a stray observation?
-- Jim
Pop3d That Doesn't Use /etc/passwd
From: Benjamin Peikes [email protected]
Do you know if there is a pop3d that does not use /etc/passwd? I want to set up mail only accounts for some people but in.pop3d that I have uses /etc/passwd. I want to set up accounts that sendmail knows how to deliver for but I don't want to put these people in /etc/passwd because then I have to worry about all the other services on the machine. Have you heard of some daemon that will do this, or a set of packages that will do this type of seperate user management? Thanks.
Ben
Ultimately this issue of restricting specific classes
of users to specific services on a system is goes
way beyond the particular services you pick. PAM
(the pluggable authentication modules) is supposed
to solve this problem eventually. That is already
included with recent versions of the RedHat distributions
(and with recent Solaris releases). However it is
still evolving -- so few of us have any idea how to
"do it right." (A fact which leads to an understandable
lack of confidence in recommending it).
So, getting back to the original question:
What POP daemon supports a user/password database that's distinct from the one used by other Unix services (/etc/passwd)?
I've heard the rumor that this can be done in qpopper but I'd like to confirm that. So I go to Yahoo! and issue the "+qpopper +account" search and get:
There is: http://www.hdshg.com/fixes/mail_patch/
... which is supposed to be a patch to qpopper to allow this. However I couldn't connect to and I couldn't find any mirror of it even after several hours of trying.
I traversed a number of links searching on strings like "+pop3 +passwd +passwd +separate" and various permuations. This was the only firm reference I found.
Another approach would be to create a custom chroot environment. This isn't as hard as it sounds. The hard part is making your binary statically linked or including the necessary libraries. The other thing you'll have to consider is whether you want the POP-only accounts to use their own "virtual mail host" (requires an IP alias or an additional interface) or whether you your smtpd to run in the same chroot "jail" -- then requiring any local account holders to also use POP (perhaps using the fetchmail client to the "localhost" target).
Here are some of the links that have more information on mail and POP in general.
Harker's sendmail References Page
Mr. Harker gives seminars and classes in sendmail
Free Servers from Eudora: Servers
Qualcomm, publishers of Eudora, also are the source of qpopper.
Passwdd/Passwd -- An authentication Daemon/Client
This isn't mail related specfically -- but relates to alternative authentication model -- a passwd daemon running on a privileged TCP port via inetd. It shows examples for supporting Eudora/APOP and using alternate passwd files. /pub/smtpd directory -- Similar to TIS FWTK smapd
Running a simpler, perhaps unprivileged smtpd to toss incoming mail into the queue is considered to be a good idea -- for isolating sendmail (which is large, powerful, complex, and has a long history of compromises). http://www.qmail.org The qmail Page
An alternative to running sendmail at all. I won't get into this debate -- I'm just including it in this list because I'll receive lots of unnecessary mail if I don't. MH Message Handler Home Page
The Rand MH is a particular mail user agent -- actually a set of programs for working with mail from a shell command line. There are several packages that provide full screen interfaces to this -- including an emacs mode/package, mh-e, which is what I use. Scripts and Patches for ISP's 4th UNIX SECURITY SYMPOSIUM -- Sendmail w/o Superuser How to Get There From Here -- Scaling e-mail to the enterprise Linux: Server-Linux FAQ
I hope all of this helps.
-- Jim
Configuration of Two Ethernet Cards
From: Carlos Gonzalez Andrade [email protected]
Date: Mon, 11 Aug 1997 23:40:16 -0700
Hi Jim.
I have a question about some problems i have while I was seting up 2 ether cards.
first . the device eth1 is not recognized when I add the line append = ether=0,0,eth1 into the lilo.conf.
You should consider putting the I/O base address, the
IRQ, and any DMA or memory address information into
this append clause in place of those zero's.
You can test these by entering them at the LILO prompt (interactively, during boot) before editing the /etc/lilo.conf file.
second . What files are necesary to set up to configure
two IP address for my machine and get runing my gateway?
I will apreciate your answer
This depends on which distribution you're using and
how closely you want to stick to their configuration
conventions. Minimally all you need is a script file
(typically located under /etc/rc.d/ and invoked by the
rc.local) with calls to the 'ifconfig,' and a 'route add'
command or two. Under Red Hat's SysV init system you'd
leave your rc.d files alone and edit some file under
your /etc/sysconfig/network-scripts/ directory (ifcfg-eth0,
and ifcfg-eth1 if I recall correctly -- it should be obvious
by browsing through those files).
-- Jim
Attaching a Console to a PC
To: Benjamin Peikes [email protected]
Date: Mon, 11 Aug 1997 23:14:37 -0700
Jim,
I'm not sure if you are the right person to ask but I figured you would be a good place to start. I have a handful of PC's that I need to be able to watch as they boot. What I would like to do is connect a dumb terminal(old laptop) to a rs-232 switch box and then be able to switch to any of the machines as I boot them. I was wondering if you knew any way to do this. Thanks.
Ben Peikes
It is possible to use a serial terminal as a console
for Linux -- given some patches. With some PC hardware
you'll have to leave the video card in their -- though
you don't need a monitor attached.
Unfortunately I don't remember where I saw these patches. I'd so a search on "+Linux +serial +console" (using the Yahoo! convention of preceding "required" terms with "plus" signs).
-- Jim
CLUELESS at the Prompt: A new column for new users
by Mike List, [email protected]

Well it's starting to happen.My learning curve is starting to settle down, and if you have been following this column, yours is too, although depending on what you want from Linux, you may have many more questions. At this point you probably are feeling more comfortable using the online resources like the comp.os.linux.??? newsgroups and some of the Linux pages that are hanging out there for you to glean info from.
Some of my regular stops are:If you use a browser the first time you visit the ftp sites you can get a good feel for the directory breakdown, but if you want to download large files ie. distributions, you should use the command line ftp, in my experience, it's faster.
Speaking of the command line ftp program, here are a few tips that can make things go more quickly. You may already be familiar with some or all, but if not, just type ...
Config, dot and .rc files
There are many ways that your linux programs can be altered to your liking, or just to make it work the way it should. Last time I gave an example of how to customize FVWM, but it hardly scratched the surface of all the things that can be done to make your linux environment truly yours.
If you type: ls -a, you'll see several files that start with ".". These are typically configurable files that among other things, create aliases for shell commands, set environment variables, geometry of X applications, and other similar functions.
Some of these "dotfiles"have eluded my attempts to alter them in the ways I'd like, but others have been extremely compliant. Some of the no-gos (for me) include .bashrc and .bash.profile. I'm sure someone will e-mail me and tell me why my aliases don't work, even though I edited the file exactly as shown in the"Bible". Others like the aforementioned .fvwmrc have had extemely gratifying results.Maybe my colleagues at "The Answer Guy" and "The Weekend Mechanic" can shed alittle more light on the subject. In the meantime, backup your dot files before altering them, by cp'ing them to, say .foo.old to keep serious problems at bay, should your editing fail to yield the desired results.
Some of the "dot files" you might want to take a look at for possible tailoring (depending on what you have installed)include your .bash.profile, your .bashrc, or .rc files for any shell you might use, .xinitrc, your window manager's .rc file, browser .rc and .bookmark files.
If you have root privilege. there are many more you have access to but be careful - some files have their own ways of being altered for instance crontabs -e is the way to edit your crontab which has the capability of taking care of routine maintenance at off hours upatedb to create a database for the find and locate commands. Usually run in the wee hours of the morning, this could be configured to run at bootup or every 12 hours or at the end of a workday. This would assure that all of the current day's work would be easily located the next day.
The /etc/ppp/ip-upand ip-down files can cause certain functions when a ppp connection is established. If you don't have one already, you can probably write one that will be noticed by the current software. The same goes for the .bashrc and .bash_profile, with the above caveat in mind.
For the most part, the lines you need to enter or alter will be essentially the same as you would use at the command line, and sometimes it will be as easy as removing the # from the beginning of the line.
Don't use a .bat!
One 'dot file that you can't edit to your liking, but could be useful just the same is .bash_history. If you cat .bash_history | sort>[filename] then less filenameyou will get an idea of what commands are used most often. You can then use this information to create shell scripts or aliases in your .bashrc or .bash.profile or other shell.rc files and save a few keystrokes.
Keep those e-mails coming in, but just so you know, I don't run linux on a new pentium with all the bells and whistles and I don't know much about stuff I haven't used, so I might not be able to help you much with tape drives, CDroms, SCSI peripherals and the like. I'll do my best to point you in the right direction,but I use a 486/66 box with IDE drives and a floppy(3.5"), a vga monitor, a cirruslogic 5428 videocard, internal modem, and an 8bit soundblaster card.I mention this, not to beg for new hardware (although...), but to give you some kind of idea what kind of hardware questions I might be of help with.
See you next month!
Everyone wants a fast computer. However, not everyone realizes that one of the most important factors of computer performance is the speed of the file system. Regardless of how fast your CPU is, if the file system is slow then the whole computer will also seem slow. Many people with very fast Pentium Pro's but slow disk drives and slower networked file systems rediscover this fact daily.
Luckily, Linux has a very fast file system called the Extended File System Version 2 (EXT2). The EXT2 file system was created by Remy Card ([email protected]). This article will show you how the EXT2 file system is organized on disk and how it gets it's speed.
There are several objectives when deciding how to lay data out upon a disk.
First and foremost, the data structure should be recoverable. This means that if there is some error while writing data to the disk (like a silly user pulling the power cord) the entire file system is not lost. Although loosing the data currently being written is often acceptable, loosing all the data on the disk is not.
Secondly, the data structure must allow for an efficent implementation of all needed operations. The hardest operation to implement is normally the hard link. When using a hard link, there are more than one directory entry (more than one file name) that points to the same file data. Accessing the data by any of the valid file names should produce the same data.
Another hard operation involves deleting an open file. If some application has a file open for access, and a user deletes the file, the application should still be able to access the file's data. The data can be cleared off the disk only when the last application closes the file. This behavior is quite unlike DOS/Windows, where deleting a file means that applications who have already begun to access the file loose all further access. Applications that use this UNIX behavior concerning deleted files are more common than one might think, and changing it would break many applications.
Thirdly, a disk layout should minimize seek times by clustering data on disk. A drive needs more time to read two pieces of data that are widely seperated on the disk than the same sized pieces near each other. A good disk layout can minimize disk seek time (and maximize performance) by clustering related data close together. For example, parts of the same file should be close together on disk, and also near the directory containing the file's name.
Finally, the disk layout should conserve disk space. Consurving disk space was more important in the past, when hard drives were small and expensive. These days, consurving disk space is not so important. However, one should not waste disk space unnecessarily.
Partitions are the first level of disk layout. Each disk must have one or more partitions. The operating system pretends each partition is a seperate logical disk, even though they may share the same phyical disk. The most common use of partitioning is allow more than one file system to exist on the same physical disk, each in its own partition. Each partition has its own device file in the /dev directory (e.g. /dev/hda1, /dev/hda2, etc.). Every EXT2 file system occupies one partition, and fills the whole partition.
The EXT2 file system is divided into groups, which are just sections of a partition. The division into groups is done when the file system is formatted, and cannot change without reformatting. Each group contains related data, and is the unit of clustering in the EXT2 file system. Each group contains a superblock, a group descriptor, a block bitmap, an inode bitmap, an inode table, and finally data blocks, all in that order.
Some information about a file system belongs to the file system as a whole, and not to any particular file or group. This information includes the total number of blocks within the file system, the time it was last checked for errors, and so on. Such information is stored in the superblock.
The first superblock is the most important one, since that is the one read when the file system is mounted. The information in the superblock is so important that the file system cannot even be mounted without it. If there were to be a disk error while updating the superblock, the entire file system would be ruined. Therefore, a copy of the superblock is kept in each group. If the first superblock becomes corrupted, the redundent copies can be used to fix the error by using the command e2fsck.
The next block of each group is the group descriptor. The group descriptor stores information on each group. Within each group descriptor is a pointer to the table of inodes (more on inodes in a moment) and allocation bitmaps for inodes and data blocks.
An allocation bitmap is simply a list of bits describing which blocks or inodes are in use. For example, data block number 123 is in use if bit number 123 in the data bitmap is set. Using the data and inode bitmaps, the file system can determine which blocks and inodes are in current use and which are available for future use.
Each file on disk is associated with exactly one inode. The inode stores important information about the file including the create and modify times, the permissions on the file, and the owner of the file. Also stored is the type of file (regular file, directory, device file like /dev/ttyS1, etc) and where the file is stored on disk.
The data in the file is not stored in the inode itself. Instead, the inode points to the location of the data on disk. There are fifteen pointers to data blocks within each inode. However, this does not mean that a file can only be fifteen blocks long. Instead, a file can be millions of blocks long, thanks to the indirect way that data pointers point to data.
The first thirteen pointers point directly to blocks containing file data. If the file is thirteen or fewer blocks long, then the file's data is pointed to directly by pointers within each inode, and can be accessed quickly. The fourteenth pointer is called the indirect pointer, and points to a block of pointers, each one of which points to data on the disk. The fifteenth pointer is called the doubly indirect pointer, and points at a block containing many pointers to blocks each of which points at data on the disk. Perhaps the picture below will make things clear.
Figure showing the pointers between an inode and it's associated
data.
This scheme allows direct access to all the data of small files (files less than fourteen blocks long) and still allows for very large files with only a few extra accesses. As the table below shows, almost all files are actually quite small. Therefore, almost all files can be accessed quickly with this scheme.
| File Size (bytes) | 0-768 | 769-1.5K | 1.5K - 3K | 3K - 6K | 6K-12K | 12K and up |
| Occurence (%) | 38.3 | 19.8 | 14.2 | 9.4 | 7.1 | 10.1 |
| Cumulative (%) | 38.3 | 58.1 | 72.3 | 81.7 | 89.8 | 99.9 |
Table showing occurence of various file sizes.
Inodes are stored in the inode table, which is at a location pointed to by the group descriptor within each group. The location and size of the inode table is set at format time, and cannot be changed without reformatting. This means that the maximum number of files in the file system is also fixed at format time. However, each time you format the file system you can set the maximum number of inodes with the -i option to mke2fs.
No one would like a file system where files were accessed by inode number. Instead, people want to give textual names to files. Directories associate these textual names with the inode numbers used internally by the file system. Most people don't realize that directories are just files where the data is in a special directory format. In fact, on some older UNIXs you could run editors on the directories, just to see what they looked like internally (imagine running vi /tmp).
Each directory is a list of directory entries. Each directory entry associates one file name with one inode number, and consists of the inode number, the length of the file name, and the actual text of the file name.
The root directory is always stored in inode number two, so that the file system code can find it at mount time. Subdirectories are implemented by storing the name of the subdirectory in the name field, and the inode number of the subdirectory in the inode field. Hard links are implemented by storing the same inode number with more than one file name. Accessing the file by either name results in the same inode number, and therefore the same data.
The special directories "." and ".." are implemented by storing the names "." and ".." in the directory, and the inode number of the current and parent directories in the inode field. The only special treatment these two entries recieve is that they are automatically created when any new directory is made, and they cannot be deleted.
The easiest way to understand the EXT2 file system is to watch it in action.
To explain the EXT2 file system in action, we will need two things: a variable that holds directories named DIR, and a path name to look up. Some path names have many components (e.g. /usr/X11/bin/Xrefresh) and others do not (e.g. /vmlinuz).
Assume that some process wants to open a file. Each process will have associated with it a current working directory. All file names that do not start with "/" are resolved relative to this current working directory and DIR starts at the current working directory. File names that start with "/" are resolved relative to the root directory (see chroot for the one exception), and DIR starts at the root directory.
Each directory name in the path to be resolved is looked up in DIR as it's turn comes. This lookup yields the inode number of the subdirectory we're interested in.
Next the inode of the subdirectory is accessed . The permissions are checked, and if you have access permissions, then this new directory becomes DIR. Each subdirectory in the path is treated the same way, until only the last component of the path remains.
When the last component of the pathname is reached, the variable DIR contains the directory that actually holds the file name we've been looking for. Looking in DIR tells us the inode number of the file. Accessing this final inode tells where the data for the file is stored. After checking permissions, you can access the data.
How many disk accesses were needed to access the data you wanted? A reasonable maximum is two per subdirectory (one to look up the name, the other to find the inode) and then two more for the actual file name itself. This effort is only done at file open time. After a file has been opened, subsequent accesses can use the inode's data without looking it up again. Further, caching eliminates many of the accesses needed to look up a file (more later).
Put the starting directory in DIR.
Put the pathname in PATH.
While (PATH has one than one component)
Take one component off PATH.
Find that component in DIR yielding the INODE.
If (permissions on INODE are not OK)
Return ERROR
Set DIR = INODE
End-While
Take the last component off PATH yielding FILENAME.
Find FILENAME in DIR yielding INODE.
If (permission on INODE are not OK)
Return ERROR
Store INODE with the process for quick later lookup.
Return SUCCESS.
|
Pseudo-code for opening a file.
When a new file or directory is created, the EXT2 file system must decide where to store the data. If the disk is mostly empty, then data can be stored almost anywhere. However, performance is maximized if the data is clustered with other related data to minimize seek times.
The EXT2 file system attempts to allocate each new directory in the group containing it's parent directory, on the theory that accesses to parent and children directories are likely to be closely related. The EXT2 file system also attempts to place files in the same group as their directory entries, because directory accesses often lead to file accesses. However, if the group is full, then the new file or new directory is placed in some other non-full group>
The data blocks needed to store directories and files can found by looking in the data allocation bitmap. Any needed space in the inode table can be found by looking in the inode allocation bitmap.
Like most file systems, the EXT2 system relies very heavily on caching. A cache is a part of RAM dedicated to holding file system data. The cache holds directory information, inode information, and actual file contents. Whenever an application (like a text editor or a compiler) tries to look up a file name or requests file data, the EXT2 system first checks the cache. If the answer can be found in the cache, then the request can be answered very quickly indeed without using the disk.
The cache is filled with data from old requests. Therefore, if you request data that you have never requested before, the data will not be in the cache, and must be retrieved from disk. Luckily, most of the time most people ask for data they have used before. These repeat requests are answered quickly from the cache, saving the disk drive much effort while providing the user quick access.
Of course, each computer has a limited amount of RAM available. Most of that RAM is used for other things like running applications, leaving perhaps 10% to 30% of total RAM available for the cache. When the cache becomes full, the oldest unused data (least recently used data) is thrown out. Only recently used data remains in the cache.
Since larger caches can hold more data, they also can satisfy a larger number of requests. The figure below shows a typical curve of the total cache size versus the percent of all requests that can be satisfied from the cache. As you can see, using more RAM for caching increase the number of requests answered from the cache, and therefore increase the apparent speed of the file system.

Figure #1: A typical curve of total cache
size vs. the number of requests satisfied from the cache.
It has been said that one should make things as simple as possible, but no simpler. The EXT2 file system is rather more complex than most people realize, but this complexity results in both the full set of UNIX operations working correctly, and good performance. The code is robust and well tested, and serves the Linux community well. We all owe a debt of thanks to M. Card.
The data for the figures in this paper can all be found in my dissertation Improving File System Performance with Predictive Caching. See the URL http://euclid.nmu.edu/~randy .
An excellent paper with more technical detail can be found at http://step.polymtl.ca/~ldd/ext2fs/ext2fs_toc.html .
Some performance data can be found at http://www.silkroad.com/linux-bm.html .
Perhaps you have read my article about Using a
Laptop in Different Environments. There I described an
easy way to setup a Linux laptop to boot into different
network configurations. I mentioned that setting up a shell
variable called PROFILE is useful not only for
configuring the network but also the windowmanager.
rlogin-sessions.
After fiddling some time with patching different
fvwm configuration files on different machines I found this to be a
pain. A typical .fvwm95rc is about 900 lines. Keeping several of them
in sync is not the thing I like.
cpp, the C-preprocessor ! fvwm 2.xx as well
as fvwm95 are configured by a central file. fvwm95 is derived from
fvwm, so the basic idea applies to both. Let me show you the details
using fvwm95. I keep my fvwm95 configuration in the file ~/.fvwm95rc-cpp.
You can use the system default setup in
/etc/X11/fvwm95/system.fvwm2rc95 as starting point.
Look at this code fragment from my .xinitrc (For me, .xsession is
linked to .xinitrc):
... # I need the value of PROFILE for generating .fvwm95rc # netenv contains an assignment like e.g. PROFILE=32 if [ -r /tmp/netenv ]; then . /tmp/netenv fi # Now the actual .fvwm95rc is generated depending on the value of PROFILE cpp -lang-c++ -D PROFILE=$PROFILE ~/.fvwm95rc-cpp ~/.fvwm95rc exec fvwm95 # exec saves the extra memory for a no longer useful shell ... ...The shell variable
PROFILE contains the information about the current
environment. The file /tmp/netenv is set up by init when going to run
level 2. I described this in the article mentioned above.
Obviously you need cpp, which comes either as an extra package or as
part of gcc. Yes, I know that there is a module FvwmCpp (which calls
cpp) - but I never managed to get it work.
One advantage of the old-fashioned style of configuration files is that you can put comments in. You really should do this ! All that hidden dot files in your home directory make up your personal environment (these files will never be touched by a system update). Having comments will make it easier to maintain this environment.
system.fvwm95rc comes in shell style comment syntax (so does
fvwm). You can't feed this into cpp. I didn't like
traditional c-style comments in a configuration file, so I switched
all these comment lines
# this is a useful comment
into c++-style comments
// this is a useful comment
(hail emacs !). Calling cpp with
-lang-c++
tells cpp to preprocess c++-code. A hint for those, who are not
familiar with cpp: cpp strips off the comment lines of the input
file. You probably will get output with a lot of blank lines.
.fvwm95rc-cpp.
Of course, everything herein is strongly a matter of personal taste.
I don't like to stress my eyes. So I hate small letters, I barely can
read them in the evening of a long day ... So my desktop has 4x2 pages.
Each page is assigned to one application (or a few). I use
<Alt><F1> to <F8> to
switch quickly between pages. Using the fabulous fvwm95 mini icons my
screen holds the FvwmTaskBar and on the right hand side a column
holding some icons. This way I can maximize the application window.
The screenshot should make it clear.
FvwmButtons section like this:
*MiniButtons - mini-edit.xpm Exec "Xemacs" /usr/bin/xemacs \
-geometry EMACS_GEO &
EMACS_GEO is to be substituted by
cpp. I put all the #define in the
beginning of my .fvwm95rc-cpp. Basically it reads like this
#if PROFILE == 30 || PROFILE == 31 || PROFILE == 32
#define EMACS_GEO 80x25+0+480
#else
#define EMACS_GEO 96x31+0+767
#endif
Whenever I'm on my laptop, PROFILE equals 30, 31
oder 32 (at home, in the office, on customers site). The
LCD-Display has 600x420 pixel. My other systems have 17" monitors and
there I use 1024x768. The +0+480 or +0+767 pops up the xemacs window
on the leftmost page on the bottom row of my 4x2 desktop. But this is
true only when being on the very first page while clicking the
icon. I'm shure, this could be improved.
With defining
Key F5 A M GotoPage 0 1
I can conveniently switch to my xemacs window using rlogin sessions to
some well known machines. Being on a customers site I frequently have
to work with high availability configurations mostly consisting of two
machines. I call them always abba and bebe. See how this can be set
up (shortened for clarity):
DestroyFunc "InitFunction"
#if PROFILE == 30
AddToFunc "InitFunction" \
"I" Exec xsetroot -solid turquoise4 -cursor_name top_left_arrow &
+ "I" Exec xconsole -font 6x10 -geometry XCONSOLE_GEO -sb -file /dev/xconsole &
+ "I" Exec rxvt -geometry 94x28+0+0 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID1 -n TERMWIN_ID1 -cr Yellow3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO2 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID2 -n TERMWIN_ID2 -cr Red3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO3 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID3 -n TERMWIN_ID3 -cr Magenta3 &
+ "I" Module FvwmButtons MiniButtons
+ "I" Module FvwmTaskBar
+ "I" Module FvwmAuto 700
+ "I" Module FvwmPager 0 0
#elif PROFILE == 10
...
#else
AddToFunc "InitFunction" \
...
...
+ "I" Exec rxvt -geometry 94x28+0+0 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID1 -n home -cr Yellow3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO2 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID2 -n TERMWIN_ID2 -cr Red3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO3 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID3 -n TERMWIN_ID3 -cr Magenta3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO4 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID4 -n TERMWIN_ID4 -cr Green3 &
+ "I" Exec rxvt -geometry TERMWIN_GEO5 -fn DEF_FONT -ls -sb -vb \
-title TERMWIN_ID5 -n TERMWIN_ID5 -cr Blue3 &
...
...
#endif
The terminal geometry und identifiers are defined as follows:
#if PROFILE == 10 #define TERMWIN_ID1 bav@nana #define TERMWIN_ID2 nana #define TERMWIN_ID3 lulu #elif PROFILE == 20 ... #elif PROFILE == 30 ...#define TERMWIN_ID1 bav@lulu #elif PROFILE == 31 ... #elif PROFILE == 32 #define TERMWIN_ID1 bav@lulu #define TERMWIN_ID2 lulu #define TERMWIN_ID3 abba #define TERMWIN_ID4 bebe #define TERMWIN_ID5 abba #endif
cpp as shown.
Perhaps you know, that xrdb(1) also can
make use of cpp. So
you can preprocess your ~/.Xdefaults achieving the discussed advantages.
I hope you will find these ideas somehow useful !
Kind regards
Gerd
I have been involved with Unix and the Internet since '88, and with Linux since '95, but it isn't until reading Peter H. Salus' `A Quarter Century of UNIX' during this summer vacation that I see where Linux fits in into the last 25 years of operating systems development.
Unix came about as a revolt against cumbersome propriety operating systems shipped by the various hardware-vendors. In contrast, Unix was developed by a handful of people. An example of a "huge" software project in the development of Unix is `awk'--developed by three people.
UNICS (original name) was developed at Bell Telephone
Laboratories in the Summer 1969 - Fall 1970. Ken Thompson was
the initiator and Dennis Ritchie and Rudd Canaday were active
contributors.
The intent was to create a pleasant computing environment for
themselves. The hope was that others would like it also.
The basic notion at the Labs (in Dennis Ritchie's words as
quoted from the book),
It turned out Unix was easy to use and understand when compared to the competition. It was extremely compact. It wasn't until much later that anything and everything the user wanted was supplied (like vi, emacs, X, ksh, csh,... :-)).
The single most important factor behind Unix' popularity was that in the beginning the source code was practically free. Thus it was used in education and as a base for derivate systems. The universities loved it. Later, when AT&T realized that they had in Unix something of great value and tried to capitalize on that, universities were forbidden to use the source code in education. This motivated Andy Tanenbaum to write MINIX, from whence Linus Torvalds got his inspiration to write a kernel for his Intel 386, the kernel that later became Linux.
Bell Telephone Laboratories (50/50 owned by AT&T and Western Electric Company) was, by the so called "consent decree" of Jan 24, 1956 (entered into because of the Sherman Antitrust Act and a complaint filed by the Department of Justice in Jan 14, 1949), required to reveal what patents it held and supply information about them to competitors. Also, the terms of the decree required BTL to license to anyone at nominal fees. So we have this "consent decree" to thank for the phenomenal spread of Unix!
BTL had the following support policy:
This is very important: Unix begat Internet!
For a long time no one in business took Unix seriously. For AT&T it was just a legal problem. It was run on VAX'es, but it took the Digital Equipment Corporation about a decade to learn how to support a Unix system as opposed to a Virtual Machine system because of the NIH syndrome. (NIH = Not Invented Here.)
Does it sound like Linux or does it [sound like Linux] ? :-)
On 20 Nov 1974, the U.S. government filed a new antitrust action against AT&T, Western Electric, and Bell Telephone Labs. The settlement reached in 1984 dissolved Western Electric, formed the "Baby Bells" and reorganized AT&T Bell Laboratories into Bell Telephone Labs.
AT&T was now permitted to enter the hardware and software computer business. AT&T sharply raised Unix license fees ...
One reaction was Richard M. Stallman's Free Software Foundation with it's GNU (Gnu is Not Unix) project, that has given the world a wealth of free versions of Unix systems programs. Another is Keith Bostic's CSRG project to create a license free version of Unix. Today, all free Unix clones except Linux use the CSRG code, and all free Unix clones use the GNU code, Linux included.
This is very important: Internet begat GNU and CSRG, and therefore the free Unixes, Linux included. And Unix begat Internet, so therefore, Unix begat Linux. Also, as we all know, Linux is continually developed on the Internet by a looseknit band of programmers from around the world, each doing their little piece -- truly users banded together!
So where do Microsoft and others fit into this picture? DOS/Windows is just one of many systems sprung out of the fountain of Truth -- though there is much debate as to how much truth has rubbed off on them. :-)
There is a huge cultural barrier between the Unix camp and the other guys. It took DEC a decade before the DEC Unix Engineering Group was formed, and when it was, it was located in a separate location from the rest of the company.
Salus tells the story in the book:
there was a lot of animosity towards Unix up and down the
company at DEC. Armando Stettner relates how Dave Cutler,
one of DEC's engineering elite, at one point got two Unix
engineers, Armando Stettner himself and Bill Shannon, to
drive down to his office 20 minutes away to help him with,
Armando thinks it was, some SRI package on top of VMS.
They got there and Cutler was in his office. Armando and
Bill sat down at a terminal, and it just didn't do what
they expected it to do. Cutler asked them how it was, and
Armando replied that it didn't work. To this Cutler said
"Well, thank you very much" and they were dismissed.
Cutler then called their Senior Group Manager and chewed
him out and said Armando and Bill were sorry excuses for
engineers and he never wanted to see them in Spitbrook
(his office) again. Armando believes that Cutler's
disdain has been reflected in his work ever since.
Armando says:
To round this off I'd like to itemize a few general factors for the success of Unix:
Small projects
No restrictions put on creativity
Freedom
Free source
Fun
Collect a lot of great ideas that are around plus some original ideas and put them together in a very interesting, powerful way.
Users supporting themselves
Internet
Portability
Universality
Stability -- i.e., the antithesis of the continuous change needed to keep the DOS/Windows personal computer market alive. System programs don't need to change. Well designed OS's don't need fundamental changes. No need to do Windows 95 this year, Windows 97 the next and then NT. Just stick with what works!
"Us against them" -- thanks AT&T, DEC and Microsoft!
There must be a fundamental difference of thinking between the free software camp and the other guys:
The first mind-set is to share in order to gain. The other mind-set is hoarding out of fear that something is going to be taken away. Out of the latter mind-set springs the correct business-types managing their various copy-protected products, while from the sharing win-win culture, where each person's efforts becomes a multiplier toward a common goal, springs an open and nonconformistic, somewhat anarchistic type of person. The two often do not like or understand each other.
(This article is copyright Leif Erlingsson. As long as this copyright notice is preserved, and any cuts clearly marked as such, the author hereby gives his consent to any and everybody to use this text.)
(The book `A Quarter Century of UNIX' is Copyright � 1994 by Addison-Wesley Publishing Company, Inc.)
My latest roadstop in the quest for the perfect affordable portable computer stops with the IBM ThinkPad 365XD notebook. Hawked from Egghead for only $1000, and with successful reports of sticking X on this thing form the 'net, I proceeded to install Linux on this beast. The install was one of the more difficult Linux installs I have had, with a number of problems:
*Booting directly in to the RedHat install from the CD-ROM, the install could not see the CD-ROM.
The CD-ROM in a ThinkPad 365xd is a standard IDE CD-ROM. For unknown reasons this CD-ROM was invisible when I booted into the install directly from the CD-ROM. Making a RedHat install boot disk and booting from that resolved the concern. The CD-ROM was visible, and I was able to install normally.
* RedHat crashed in the middle of the install.
RedHat seems to do that sometimes, for very mysterious reasons. On the first install, RedHat crashed. I had to go back to square one and completely reinstalled. The second install of RedHat 4.2 went without incident, resulting in a functional RedHat system.
* After installing LILO, the ThinkPad refuses to boot from the hard disk.
After mutch futzing, I discovered that the BIOS refused to boot from the hard disk if it saw more than one primary partition. I configured fdisk thusly:
I made one primary partition the Linux partition, then made the swap partition the extended partition. I did this as follows:
My fdisk session went like this:
Command (m for help): n Command action e extended p primary partition (1-4) p Partition number (1-4): 1 First cylinder (1-789): 1 Last cylinder or +size or +sizeM or +sizeK ([1]-789): 741 Command (m for help): n Command action e extended p primary partition (1-4) e Partition number (1-4): 2 First cylinder (742-789): 742 Last cylinder or +size or +sizeM or +sizeK ([742]-789): 789 Command (m for help): n Command action l logical (5 or over) p primary partition (1-4) l First cylinder (742-789): 742 Last cylinder or +size or +sizeM or +sizeK ([742]-789): 789 Command (m for help): t Partition number (1-5): 1 Hex code (type L to list codes): 83 Command (m for help): t Partition number (1-5): 5 Hex code (type L to list codes): 82 Changed system type of partition 5 to 82 (Linux swap) Command (m for help): a Partition number (1-5): 1 Command (m for help): p Disk /dev/hda: 32 heads, 63 sectors, 789 cylinders Units = cylinders of 2016 * 512 bytes Device Boot Begin Start End Blocks Id System /dev/hda1 * 1 1 741 746896+ 83 Linux native /dev/hda2 742 742 789 48384 5 Extended /dev/hda5 742 742 789 48352+ 82 Linux swap Command (m for help): w
[It wrote the information to the hard disk, then exited.]
When I installed LILO, I placed LILO on the boot sector of the first (bootable) partition (/dev/hda1) instead of the master boot record (/dev/hda).
* After installing X, as per the XF86 configurations on the Linux ThinkPad survey, I was unable to start X. X would just cause the screen to become blank.
X has to be "Kicked in", so to speak, by hand. After X starts, hit Fn+F7 (the Fn and the F7 keys at te same time) to get the X display to function.
* After starting X, one can not exit X and return to a normal text display.
One can not leave X after entering it on the ThinkPad. The best workaround this problem is to edit /etc/inittab to make the default runlevel 5. This enables a mode where you can log in and log out without leaving X, using a program known as xdm.
In order to make the default runlevel 5, look for a line like this in /etc/inittab:
id:3:initdefault:
Change the line to look like this:
id:5:initdefault:
Note the number 5 instead of 3.
You may also wish to disable most of the virtual terminals in runlevel 5, since you won't be using them [1]. There are a series of lines that look like this in /etc/inittab:
1:12345:respawn:/sbin/mingetty tty1 2:2345:respawn:/sbin/mingetty tty2 3:2345:respawn:/sbin/mingetty tty3 4:2345:respawn:/sbin/mingetty tty4 5:2345:respawn:/sbin/mingetty tty5 6:2345:respawn:/sbin/mingetty tty6
Change the lines to look like this:
1:12345:respawn:/sbin/mingetty tty1 2:234:respawn:/sbin/mingetty tty2 3:234:respawn:/sbin/mingetty tty3 4:234:respawn:/sbin/mingetty tty4 5:234:respawn:/sbin/mingetty tty5 6:234:respawn:/sbin/mingetty tty6
Note that most of the above lines no longer have a '5' in them. For various reasons, it's a good idea to have an emergency virtual terminal. Linux does (or, at least, used to do) funny things without at least one virtual terminal.
* I was unable to have the kernel see a parallel port zip drive
The I/O base of the parallel port is at 0x3bc instead of 0x378. To have Linux see a parallel zip drive on the ThinkPad 365xd:
insmod ppa.o ppa_base=0x3bc
instead of simply:
insmod ppa.o
Note that the I/O base of the parallel port was determined with the MSD program on a MS-DOS boot disk.
* After entering 'suspend mode' on the ThinkPad (Fn+F4), the system would crash when I tired to exit from suspend mode.
The kernel needs to be recompiled with APM support on the ThinkPad 365xd. To do this, make sure the kernel source is installed on your system.
You can install the kernel source from the RedHat CD, as in the following example Linux session:
[root@localhost /]# mount /mnt/cdrom [root@localhost /]# cd /mnt/cdrom/RedHat/RPMS/ [root@localhost RPMS]# rpm --install kernel-source-2.0.30-2.i386.rpm
If you do not have a RedHat CD, do the procedure most appropriate for your RedHat system to install the above RPM package.
I then went to the directory /usr/src/linux, ran 'make menuconfig' and went to 'Character Devices --->', then enabled 'Advanced Power Management BIOS support' without enabling any of the other features ('Ignore USER SUSPEND', etc.).
I then made a kernel image with 'make zImage' (and waited a while, hitting the space bar every 5-10 minutes so the machine would not crash), and copied the kernel image (located in the directory '/usr/src/linux-2.0.30/arch/i386/boot' as the file 'zImage') over to /boot.
I then edited my /etc/lilo.conf so that the boot line which looked like this: image=/boot/vmlinuz looked like this: image=/boot/zImage and re-ran Lilo thusly: /sbin/lilo
** Be very careful with changing Lilo. Doing things incrrectly can make it difficult to re-enter Linux**
Once I did all this, I had a functional Linux system on my ThinkPad 365xd, which I am currently using to type this in (on the streets of Santa Cruz, no less)
Speaking of being on the streets, I find the DTSN display almost unreadable in direct sunlight, and only somewhat readable in the shade on a sunny day (fortunatly, the Pacific coast fog is strong tonight). I hear that TFT displays are a lot better in this regard. [1] The virtual terminals is something you can use to multitask in text mode with Linux. To change virtual terminals, simply hit alt and a function key between F1 and F6.
When I first began using Linux a couple of years ago, one of my goals was to be able to go on-line. At that time I was constantly rebooting into OS/2 so I could use the internet and this OS schizophrenia was becoming tiresome.
Eventually, after many chatscript iterations and minicom sessions I had a dependable PPP setup. I thought my PPP troubles were over; as time passed my command of the various pppd and chat options began to fade.
This past month my local internet service provider sold its machines and signed up with a large provider in Atlanta. When the accounts were switched over suddenly I could no longer log in and life became a bit too interesting...
A couple of years ago an ISP was happy just to have a set of working log-in scripts which could be distributed to its Windows and Mac customers. At that time most computer users were either hobbyists or professionals, and could be counted on to know what to do with the script. As the internet surged in popularity more and more customers appeared without much knowledge of basic computer usage, and the help-desks and support personnel began to be swamped with requests for set-up help. Naturally, the tendency was to move towards simpler log-in set-ups, if possible without any script at all. As customer interest in text-mode shell accounts waned, a log-in could be accomplished with little more than the username and password. This (I was informed in an e-mail from my provider) was our new log-in sequence: just the username and password.
This sounded simple enough; all I had to do was delete the expect-send sequence selection: PPP from the chat-script and all would be well. Or so I thought: using this script led to a scrolling list of errors on the console I set up to display all daemon and error messages. It looked like the router I was attempting to connect to was first trying PAP authentication, failing, then trying CHAP authentification, failing that as well; the sequence would repeat until the router would hang up in disgust.
Other variations of the chat-script I tried would result in a "serial line not 8-bit clean" message. I talked with the technician who had set up the local router and he claimed that neither PAP nor CHAP were in use; Win95 log-ins were working fine, so I was on my own.
The next step was to try logging in with Minicom, just to see what the actual log-in screen looked like. I connected and found the expected Username: and Password: prompts. I logged in and a command prompt appeared, with no sign of the typical PPP garbage characters. What now? I typed help and a list of available commands scrolled by. I was logged in to the Cisco router, evidently, and before long I found that I could telnet anywhere I liked. I could run a systat command and see which other users were logged in. The command show hosts provided a list of hosts which I could connect to, and soon I was logged in at the main WWW server in Atlanta! I'd never been logged in at an UltraSparc server running Unix SysVR4 before, and it was great fun exploring the directory structure and running real VI for the first time. I could run pine (and I ended up with yet another e-mail address) and read news with the nn newsreader.
This was all quite diverting, but didn't address the PPP problem. So soon I was back at the router's prompt. I tried typing ppp and the indicative garbage characters appeared. This looked encouraging, so I added this exchange to my chatscript and tried again. The pppd daemon was satisfied this time, and I had what looked like a real PPP session. Unfortunately, it turned out to be limited to the router and I could do nothing with the connection. Another dead-end!
At first I couldn't even log in with OS/2 when I revived an old installation and tried to dial in. Deleting the entire log-in sequence in the dialer got me online again, but even with debugging turned on I still couldn't determine just when the username and password strings were being sent to the server.
On-line once again, I was off to the newsgroups hoping to find advice.
Eventually I came across a posting in comp.os.linux.networking which contained a couple of intriguing statements. The first intimated that Win95 by default makes use of PAP authentification, but the user isn't necessarily informed of the fact. Possibly the Netscape dialer which my ISP distributes was using PAP as well, I thought. The second statement recommended using the pppd option +ua /etc/ppp/pap-secrets. I had seen this option while reading the pppd /etc/ppp/options file, but the manual listed this option as being obsolete, so I'd never tried it.
The posting's author recommended an unusual format for the pap-secrets file, unlike the format recommended in the documentation I'd been reading and unlike the sample included in my PPP installation: just a simple two-line file, the first line containing the username and the second displaying the password. No server or client names, just the two words.
I was surprised and elated when this configuration worked the first time. I had the chat-script simply dial the number and wait for the CONNECT string. The server asked for PAP authentification and I was online without even dealing with the username and password prompts, which I suppose are only for the maintainers of the router.
I'm writing this piece because I suspect that many other servers will
probably be adopting similar streamlined login procedures, and the approach
I've outlined here may prove useful in at least some of these cases. One
thing to remember is that directing the pppd debugging messages to
an unused virtual console is very helpful, most easily accomplished by
inserting the line:
*.* /dev/tty8
in your
This summer a new version of SVGATextMode was released, and thinking that many Linux users might be unfamiliar with the package, I put together this review as an introduction to a versatile and useful console utility.
Typically, Linux distributions use LILO as the boot loader, which refers to the file /etc/lilo.conf for instructions. One of the lines in the file is vga = , with either the number of a console video mode following the "=", or the word ask. If "ask" is specified, the Linux boot process is interrupted and you are asked which (EGA) video mode you prefer. An option (thankfully!) is also provided allowing the user to peruse a menu of available console video modes, which varies depending on the video chipset. With my generic S3 Virge card, these modes are offered:
It's nice to have a choice of video modes (which determine the screen font size) but these boot-time options just scratch the surface of what the newer video cards and monitors offer. SVGATextMode is a utility which borrows some of the techniques which the X-Window system uses to exploit the resources of your video system and applies them to the console screen.
SVGATextMode actually reprograms the registers of your video card, allowing many more modes than the preprogrammed modes available at boot-up. It borrows some of the techniques used by XFree86 in order to make available more console video modes. The modes provided by your video-card BIOS are EGA modes, and they run at a low refresh-rate and dot-clock compared to those used by X-windows.
The program can be either started at boot-time from one of the init-files, or at any time from the console prompt. When it starts a configuration file (/etc/TextConfig) is parsed. The defaults are very conservative. The file needs to be read and edited before any real advantage can be obtained from the program. This is due to the vast differences in capability between various video cards and monitors. As in X configuration, the correct values for your monitor's horizontal and vertical refresh rates need to be entered in the TextConfig file. If you've successfully configured X you shouldn't have any problems with SVGATextMode.
SVGATextMode is what I consider to be a "mature" package, in that it has been under development long enough to have received contributions and bugfixes from a worldwide community of users. Many video cards are supported, though I don't think quite as many as XFree86 supports.
In the default /etc/TextConfig file many of the lines are high-resolution modes contributed by users. Once you have entered your video chipset and monitor timings into the file, the command SVGATextMode -n [mode] will let you know if your hardware can support the mode without actually starting the program. Once you've found some promising modes just eliminate the "-n" from the command and with any luck you'll have the new text mode visible on your console screen. Possibly the screen will be corrupted. Running the SVGAlib utility savetextmode before trying a new mode, then if corruption appears restoretextmode afterwards ought to allow recovery of your previous default text mode. It will take some experimentation, but the package is very well documented and is worth the trouble.
There are some included modes with 160-character wide screens, which can be very useful while running an editor which allows two 80-character pages to be displayed side-by-side. Emacs can do this, and there is a LISP package available called follow-mode which allows both pages to scroll relative to each other.
SVGATextMode doesn't just allow more characters to be displayed on the screen. Even relatively low-resolution modes will look crisper and be easier to read due to the higher refresh rates typically used. The most dramatic advantages, naturally, are evident with newer, more powerful video-cards and large monitors, but even with my middle-of-the-road equipment the utility is well worth using.
If you use Dosemu from the console there can be problems. I have to reset the text-mode to my old default 80x43 mode before starting Dosemu or I get unrecoverable corruption requiring a reboot. I haven't had any problems switching from a console session to X and back, but, just as with X-windows, performance varies depending upon the video-card and monitor involved. Read the documentation; it's very complete and a great help while getting started.
The source package (version 1.6) can be retrieved from the Sunsite archive site or one of its mirrors, in this directory. A binary package for Redhat systems is available here, and a Debian binary can be downloaded from here.
Marco Macek, a Slovenian computer-science student, has been developing a quite powerful and configurable editor called FTE for the past couple of years. FTE is a multi-platform folding editor, available for Linux, OS/2, DOS, and Windows; I wrote a short review of an earlier beta in issue 7 of LG. Lately Marco has turned his hand to developing a new window-manager. Unlike some Linux projects, which are released to the FTP sites in the early stages of development, the Ice window-manager seems to have been under development as a non-public project throughout the early beta versions. It just showed up one day in the Sunsite incoming directory in a remarkably complete and usable form.
Lately window-managers seem to be proliferating, with offshoots and variants of fvwm predominating. Icewm is in large part inspired by the OS/2 Workplace Shell interface. Though OS/2 has been never gained the market acceptance its adherents have hoped for, the Workplace Shell is a remarkably advanced object-oriented GUI, and Macek has attempted to adapt some of its "look-and-feel" to the Linux environment. Another influence is the common Windows 95 interface, which does have some useful features worth emulating.
Win95's bottom-of-the-screen icon bar , with its cascading menus and dynamic
window indicators, has been nicely reproduced in Icewm. The equivalent of
the "Start" menu (which functions much like Win95's) has a "Linux" label with
a penguin icon.

The general appearance of the windows (borders, titlebars, et al) is very
reminiscent of OS/2. Various types of "X" kill buttons are available, but the
general appearance of the window-borders seems to be hard-coded; that is, not
configurable. Here's a screenshot of a typical window:
I liked the cascading mouse button menus, with a different menu shown for
each mouse button. The Enlightenment window-manager has a similar feature.
These menus are hierarchical and behave like their OS/2 equivalents.
This window-manager really doesn't have such compellingly new features that many long-time Fvwm2 or AfterStep users would want to adopt it, but for new Linux users more familiar with Win95 or OS/2, the similarities might serve to ease the transition. It compiled easily on my 2.0.30 system, and it seemed to be stable and dependable.
The source archive is available from the icewm home-page, as well as the sunsite FTP site. Icewm's home page also has Redhat RPM's of the source.
Occasionally I use my Linux machine at home to write code that I intend to compile on a remote machine.
While maintaining open ftp and telnet connections to the remote machine to handle the transfer and compilation steps is a manageable solution, I decided to explore ssh and make to develop a more automated method.
The benefits of my solution:
My first step was to set up ssh and related tools in order to allow secure copying of files to my remote system. While setting up a .rhosts file is a (barely) acceptable solution, my IP address and name is different each time I dial in, and it would be rather awkward to change the remote system's .rhosts file each time I dialed in.
ssh allows me to use a much more secure form of authentication to copy files and execute remote commands.
Once I had ssh behaving properly, I used Emacs' info facility to explore implicit rules in makefiles, and wrote a simple makefile to handle the file transfers and remote compilation.
As an example of the intended effect, assume my remote machine is called "remote" (and my local machine "local"), and I've just modified a source file called daemon.c. I would like to execute the following commands in an automated fashion (note that scp is a secure copy command packaged with ssh, and that the -C option specifies compression, useful for dialup connections):
scp -C daemon.c jdaily@remote:~/source-directory ssh -C remote "cd source-directory && make"
First, I needed sshd running on the remote system to handle my secure connections. Fortunately, sshd was already running on the remote system in question, but according to the man pages, it can be run as any user, and is restricted to handling connections for that user (which should be quite sufficient for our needs).
Then, I needed to install the ssh toolset on my local machine. Again, ideally these would be installed in a public binary directory such as /usr/local/bin, but any user can install them in his/her home directory.
I also wanted a key which would allow me to authenticate myself between systems, and which would eliminate the need to type my password each time I tried to run one of the ssh commands. For this, I just ran ssh-keygen, and made sure to not give a pass phrase, so that none would be needed to use my private key to establish the connection.
[jdaily@local ~]$ ssh-keygen Initializing random number generator... Generating p: ............++ (distance 186) Generating q: ......................................++ (distance 498) Computing the keys... Testing the keys... Key generation complete. Enter file in which to save the key (/home/jdaily/.ssh/identity): <CR> Enter passphrase: <CR> Enter the same passphrase again: <CR> Your identification has been saved in /home/jdaily/.ssh/identity. Your public key is: 1024 35 718535638573954[...] jdaily@local Your public key has been saved in /home/jdaily/.ssh/identity.pub
Once I had a public key, I used scp to copy it to the remote machine.
[jdaily@local ~]$ scp -C ~/.ssh/identity.pub jdaily@remote:~/.ssh/key jdaily's password: <entered my remote password>
Then I logged into the remote host and copied the key file into ~/.ssh/authorized_hosts. If that file already existed, I would have appended the key file.
Following all this, I could run ssh and scp without needing either a password or a pass phrase to connect to remote.
Now I needed a makefile to automate my system. Ideally, the files on the remote machine would be checked to see if they were older than the files on my local machine, and if so, they would be copied over. To simplify matters, I decided to keep a record of the "last transferred date" for each file by touching a corresponding file each time I copied a source file over.
As an example, when I transferred a newer copy of daemon.c over, I touched daemon.ct in the same directory. Any transfer of a .h file would be marked by the creation of a file with a .ht suffix.
After poking around the info file for make, I came up with the following makefile.
TRANSFER=scp REXEC=ssh SSHFLAGS=-C # Compress data REMOTE=jdaily@remote:~/source-directory FILES=debug.ht messages.ht client.ct daemon.ct queue.ct queue.ht %.ht : %.h $(TRANSFER) $(SSHFLAGS) $< $(REMOTE) touch $@ %.ct : %.c $(TRANSFER) $(SSHFLAGS) $< $(REMOTE) touch $@ all-done: $(FILES) $(REXEC) $(SSHFLAGS) remote "cd source-directory && make" touch all-done
This had one limitation in particular; I was unable to specify command-line arguments for make on the remote machine without writing them directly into the makefile on my local system. While this was fine for the current application, I decided to generalize it by creating a run-make shell script, which would handle the remote execution of make after calling make on the local system.
Here is my run-make shell script:
#!/bin/sh make echo ssh -C remote \"cd source-directory \&\& make $*\" ssh -C remote "cd source-directory && make $*"
I then removed the line from my makefile which remotely ran make.
Here's the output from a successful compilation sequence.
cd ~/source-directory/ ./run-make scp -C debug.h jdaily@remote:~/source-directory touch debug.ht scp -C messages.h jdaily@remote:~/source-directory touch messages.ht scp -C client.c jdaily@remote:~/source-directory touch client.ct scp -C daemon.c jdaily@remote:~/source-directory touch daemon.ct scp -C queue.c jdaily@remote:~/source-directory touch queue.ct scp -C queue.h jdaily@remote:~/source-directory touch queue.ht touch all-done ssh -C remote "cd source-directory && make " gcc -Wall -Wstrict-prototypes -Wmissing-prototypes -g -c queue.c gcc -Wall -Wstrict-prototypes -Wmissing-prototypes -g -DPORT=3000 -o daemon daemon.c queue.o -lsocket -lthread gcc -Wall -Wstrict-prototypes -Wmissing-prototypes -g -DPORT=3000 -o client client.c -lsocket Compilation finished at Sat Aug 9 01:22:19
make is a standard Unix utility. GNU's make comes with most, if not
all, Linux distributions.
Ever wish you could do more to promote Linux and yet you never seem to
have enough time? Now for a few pennies worth of electricity per day you
can put your Linux machine to work promoting Linux!
There are a number of distributed computing projects in progress or being
organized, and Linux Advocacy teams are one method available to us which
can help raise the visibility of Linux.
What I'd like to describe in this article is one such effort
called the
RSA Data Security
Secret-Key Challenge.
This article will describe
what the project is;
why we are doing this and
how it might benefit Linux and
how to get started.
There is also a section on
who is involved;
other links for further information and
when to get involved
at the end.
The
Secret-Key Challenge
is a contest sponsored by
RSA Data Security
which is being used primarily to further research into the strength of
encryption standards. The DES challenge was won back in June. RSA is
offering a $10,000US prize to the winning team which breaks the
RC5-32/12/7 challenge which uses a 56 bit key. The challenge has
been running since January 28th, 1997.
The status of the various challenges can be seen
here.
The method being used for cracking the code by the various groups
is a brute force check of the entire 2^56 keyspace.
To give you an idea of the magnitude of the problem, consider that a
single fast Pentium Pro based system would take in excess of 4000 years
to run through the entire keyspace. A 200 Mhz Pentium would take about
9000 years.
Promoting Linux is the main reason we are participating in
this effort. We would like to raise public awareness of Linux, and this seems
like one of many good avenues for doing it. It is a relatively easy and fun
way to get a large number of Linux users involved in a publicity effort.
Linux is in one of those "chicken-and-egg" situations at the
moment. We need to make more software companies aware that Linux is a
market force to be recconned with. With more software, it will be easier to
convince more users, which will convince more companies etc. A snowball
effect is what we need to break off the plateau we're on.
There are many operating system advocacy groups participating in the effort.
One of the strongest ones at the moment is Apple. It seems like they've
been putting all their available systems into the effort and are currently
ranked number one in the Bovine effort. This is the one to beat!
The other Linux advocacy group
[email protected] is in second
place on Bovine, but they do not seem to have a presence in the Cyberian
effort.
The group we are involved with,
[email protected]
is moving up from behind very quickly on Bovine,
and are consistantly in the Top 20 teams on Cyberian for the key rates.
Naturally we hope that you'll consider the team which we are involved with,
but both Linux teams have similar goals and reasons for being, and either
team would be a good choice.
To prove that 56-bit encryption is insufficient. It is high time for the U.S.
government to rethink the current encryption export policies and standards.
Stronger encryption is readily available and the belief that
"bad-guys" might restrict themselves to using
encryption that could be tapped by the government does not make sense.
It is fun to watch your system work on the project, see the results and get into
mild competitions with other teams. Your system is probably idle most of the
time and it is satisfying to know that all of the
"idle-cycles"
can now be put to productive use!
Most groups and teams have some methods available for looking at the statistics.
Check into these sites on a regular basis, and see how well your team is doing!
The competitive aspect can spur growth as it motivates people to get other
people involved. This is good!
There are three overall efforts working on the RSA RC5 Challenge that we
know of.
Each one has different client programs to run and different procedures
to follow.
They also each have their own pros and cons.
Each overall effort is also divided up into "teams".
We believe
that only the first two groups have active Linux Advocacy groups,
but we may be
mistaken. (The third group had a team called Linux!, but did not have
a web address or a way to contact them which we could see.)
Copyright © 1997, John R. Daily
Published in Issue 21 of the Linux Gazette, September 1997Spare Cycles Needed for Promoting Linux
By Bill Duncan,
[email protected]
What?
Why?
Promoting Linux
Helping to Change Encryption Restrictions
Having Fun!
How?
The team we are involved with, Team Linux, has members involved with both Bovine and Cyberian, so we will describe both here.
We will also assume that you are using a Linux machine, although we (Team Linux) don't restrict you to using Linux. Our feeling on the matter is that the other machines on our team are "Linux Sympathasizers" or "Linux Wannabee" machines! ;-)
All groups work on the basis of keyservers handing out work for the distributed systems, or client systems (that's you and me) to work on. There is very little network traffic to do this. Basically the keyservers hand out a range of keys to work on. Your system then checks each key by brute force and contacts the keyserver again when it needs more work to do. The programs work at very low priority (nice-level) so that you shouldn't notice any change in interactive sessions, effectively only using "idle cycles". The client system also tells the server which range it has checked so that the numbers can show up in your team's statistics. (This is the fun part.)
The following will not be an exhaustive description of either system but will give you a few pointers on setting up. For more information, see your team's Web pages. Hopefully, this get you started and show you how easy it is.
The Bovine effort has a lot going for it. They are well organized; have fast client programs for a number of platforms; have checked a larger portion of the key space and will be giving away a larger portion of the winnings (should they win). They have stated that they will give $8000US of the winnings to Project Gutenberg which is a very worthwhile cause. They are keeping $1000US and will give $1000US to the winning team.
Both Linux teams will be giving all the prize money away. The [email protected] group will be donating the money to Linux International, while the Team Linux group is leaving it to members to vote on, and may well end up doing the same. Team Linux is also in discussions with several other companies about additional sponsorship for a worthy Linux cause. We will have an announcement about this soon.
Both [email protected] and the team we are involved with, Team Linux (with an email of [email protected]) are represented in this group. You may pick either team if you choose to use the Bovine system.
The first thing to do is to get a copy of the client program and unpack the archive into an empty directory. At the time of this writing, the latest version was v2 build 4 and the Linux archive contains:
-rwxrwxr-x bovine/rc5 292892 Aug 7 05:06 1997 rc5v2b4/rc5v2 -rw-rw-r-- bovine/rc5 2085 Aug 6 22:11 1997 rc5v2b4/README.TXT
You'll notice that the files are containted in a subdirectory relative to where you unpack them. So if you unpack in your home directory you will create a subdirectory called rc5v2b4 containing the files. (I also create a symlink [symbolic link] here, to make typing easier. Pick a name which is easier to type such as bovine. You can then use this as an alias.)
ln -s rc5v2b4 bovine
The Bovine system uses one program which both does the key checking and also maintains a cache of keys, contacting a keyserver when it needs more work, and checking in the finished blocks.
Configuring the Bovine client involves running the client program with the -config option. You will then be presented with a menu, which should be similar to the one reproduced here:
CLIENT CONFIG MENU ------------------ 1) Email to report as [default:[email protected]] ==> [email protected] 2) Blocks to Buffer [default:5] ==> 5 3) Blocks to complete in run [default:0] ==> 0 4) Hours to complete in a run [default:0] ==> 0 5) Keys per timeslice - for Macs etc [default:65536] ==> 65536 6) Level of niceness to run at [default:0] ==> 0 7) File to log to [default:] ==> 8) Network communication mode [default:1] ==> 1 14) Optimize performance for CPU type [default:-1] ==> -1 0) Quit and Save
The important one to change is "1". This email address you add here determines which team your blocks will be counted for. This is case sensitive, and does not tolerate typos, so be careful when typing this in and double check.
Press the "1" key, followed by the "Enter" key and you will be presented with the following prompt:
Email to report as (64 characters max) [[email protected]] -->
If you decide to count your blocks for [email protected] then enter it here.
If you decide to work with Team Linux then you need to enter [email protected]. (The reason we don't use [email protected] on Bovine is that we received our teamlinux.org domain after actually starting the effort. The Bovine group was unwilling to move our stats to the new email address so we had to keep the old one to maintain our block counts. The [email protected] email address actually belongs to Eric P. Anderson, who started Team Linux.)
If you are only connected to the net part time, you should consider buffering a larger number of blocks. Assuming that you connect once per day, you'll need to get at least a day's worth and maybe a bit more, for good measure. (The limit is 200 on the latest clients I think.) If you are connected to the 'Net full time, then you can leave this at the default setting.
I also suggest that you define a log file, perhaps /var/tmp/bovine.log might be a good choice. This is all you really need to define unless you have specific needs, such as getting around a firewall. (These subjects are beyond the scope of this article, and you should consult the Bovine Client Documentation for more help if you run into difficulties. They also maintain several mailing lists where you might find additional help.)
At this point, save the setup by pressing the "0" key, and you should be ready to test it out. The configuration file which is saved is called rc5v2.ini, and is placed in the current directory.
Test it out! Type the name of the program and watch it go! (We usually leave it running with a spare xterm or on one of the text consoles. One nice thing about the Bovine client is that it gives you feedback on how far through each block it is.)
Personally, we find the Cyberian Effort more satisfying, although it is not without its problems. They have been going through some difficulties on their server in the last week while one of the key developers was away in China. (This should be cleared up by the time you read this.) They also only have one server whereas Bovine have many, so Cyberian are currently more prone to having problems. Lastly, they have not been working as long as Bovine, so have not checked as much of the keyspace.
On the positive side, Cyberian have far better stats which make them much more fun to be involved with. Currently, the Bovine stats are only updated once per day and do not give you access to your individual numbers. The Cyberian stats are updated every 10 minutes or so and gives you a list of all of the team members as well as your overall team statistics.
This is a great boon for people getting involved as they can see themselves up on the board within minutes! Cyberian also has many more categories of numbers and graphs to delight the people involved.
Lastly, the Bovine effort is offering $1000US to the winning team, while the Cyberian effort is offering $5000US. This would mean more money for a worthwhile Linux effort, should one of the Linux teams win. Note that the Bovine group is giving the bulk of the money to a worthwhile cause, it's just not a Linux cause.)
At the time of this writing, we believe that the only Linux advocacy group here is Team Linux. The email address they are using here is: [email protected].
First, you need to download their client program. Pick the appropriate one for your architecture. We assume that most of us will be using the "Client v3.04 for Linux [X86]" although others are available.
This tar archive will unpack in your current directory so you should make a directory for it: $HOME/cyberian, for example, then change to that directory.
Unpacking with tar tvzf Linux-x86.bin304.tgz will give you the following files:
-rwxrwxr-x tic0/tic0 20315 Jul 25 15:08 1997 rc5client -rwxrwxr-x tic0/tic0 18093 Jul 25 15:08 1997 sa_simple
The Cyberian system uses these two programs: one (rc5client) which checks the keys and the other (sa_simple) which maintains the cache and contacts the server when necessary. Both programs will list the available options if you run the program with "-\?". (The backslash may be necessary to escape the question mark on some shells.)
You will need to contact the server to load the initial cache of blocks at this point. For now, run
sa_simple -1
If everything works OK, you should see a message saying that the server has been contacted and that your cache has been loaded. If the program has difficulty contacting the server, you will see repeated messages to that effect. If this condition lasts more than ten minutes or so, then there may be a problem. See the Cyberian or Team Linux Websites for more details. It may be a networking issue, or it may be that their server is still having some problems.
The Cyberian system does not use configuration files, nor does it create logfiles; so all options must be supplied on the command line. (We like to use logfiles to maintain a record of what was done and to see what it is doing occasionally.) You can automate this by creating a shell script such as the following:
#!/bin/sh
#
# Run the Cyberian client programs:
# (This version is for part-time connections, full-time connections don't
# use the -1 option on sa_simple, or the -q option on rc5client)
#
MY_EMAIL=yourname@yourdomain # Change This!!!
TEAM="[email protected]"
LOW_WATER_MARK=500
HIGH_WATER_MARK=1000
export TEAM HIGH_WATER_MARK LOW_WATER_MARK MY_EMAIL
sa_simple -1 -l $LOW_WATER_MARK -h $HIGH_WATER_MARK > /var/tmp/sa_simple.log 2>&1 &
rc5client -t $TEAM -e $MY_EMAIL -N -q -n19 > /var/tmp/rc5client.log 2>&1 &
With a shell script such as this you can find out what is happening at any
time by doing a
"tail -f /var/tmp/rc5client.log" or
"tail -f /var/tmp/sa_simple.log".
(In fact, we just leave a few xterms running with a tiny font,
so we can keep an eye on them while doing other things.)
Assuming that everything is running OK, you can start seeing your own email address in your team's statistics in a very short period of time. After a few hours of processing, make a connection to the net again (if you are dialing in part time), and run sa_simple -1 by itself. After the server has acknowledged your blocks, you should be able to do a search and see your email address show up here in about 15 minutes!
Another nice feature which we like about Cyberian is the ability to see what is left in the cache. This is very useful for users with part-time connections. The following is a script we use to summarize what is in the cache. You can use this as is, or even modify it to give you estimates of the number of hours left. If you have trouble cutting and pasting from here, you can find it on the Team Linux site.
#!/bin/sh
#
# @(#) cache.sh - summarize rc5 cache information dump
# Author: Bill Duncan, [email protected]
#
# Note: make sure rc5client is in your PATH. I assume current directory.
PATH=$PATH:
rc5client -d |
awk '
BEGIN {
F = "%-6s %4d %s\n"
}
FNR == 1 { next }
NF > 0 {
time = $2
$1 = $2 = ""
s = sprintf("%6s~%s", time, $0)
a[ s ]++
}
END {
for (i in a) {
split(i, b, "~")
printf F, b[1], a[i], b[2]
total += a[i]
if (i ~ /COMPLETED/)
done += a[i]
else
notdone += a[i]
}
# sort these lines to the end
printf "~\n"
printf F, "~", done, " DONE"
printf F, "~", notdone, " NOT DONE"
printf F, "~", total, " TOTAL IN CACHE"
}' |
sort | sed 's/^~/ /'
This script will give you a display such as the following:
122:59 27 COMPLETED REPORTING
125:47 101 COMPLETED REPORTING
137:15 93 COMPLETED
137:15 125 COMPLETED REPORTING
150:26 1 RESERVED
150:26 4
5 NOT DONE
346 DONE
351 TOTAL IN CACHE
This display tells us that we need to connect to the server soon
as we only have 5 blocks to go before running out! The numbers down
the left column are the number of hours and minutes left before that
block expires. The middle column is the number of blocks with that
specific expiry. The rest of the line is a status, with "RESERVED"
being the block currently being worked on and no status means that the
group has not been started yet.
Stats, Numbers and Graphs
As we have mentioned elsewhere, the Cyberian group pay more attention to the statistics and graphs, which we tend to think are more fun for people.
Both groups tend to pay alot of attention to the blocks already completed. This is like saying that someone has bought 10,000 losing lottery tickets vs. someone else who has only bought 10. The prize is not given to the group with the most losing tickets! Both teams have an equal chance of buying the next winning lottery ticket!!
More important is the current rate at which the tickets are being bought, or in our case, the rate at which key blocks are being checked.
If you compare teams on that basis, it gives a more realistic relative probability on which team will find the secret key and win the prize money.
Having said all that, watching the numbers and the graphs, and comparing your team's numbers with other teams is all part of the fun.
The Bovine stats recently had an overhaul but is still only updated once per day. For example: only team statistics are shown, without mentioning individual efforts.
The
Cyberian stats
and their
search facility
are a joy to use. They provide almost instant feedback for anyone
getting involved as you can usually find your entries within minutes
of contacting the server. You can also see how your contribution has
helped the overall team effort.
Who?
Why two teams? Why don't we just join up with the other team, and combine our numbers? We've been asked this probably the most since Eric Anderson started Team Linux.
The reason is that we feel that "friendly" rivalry will benefit both teams and help get people excited about getting involved. The benefit to Linux will hopefully be greater participation and better visibility.
Both teams have the same main goals in mind with promoting Linux the highest on the list. However, we both have different ways of going about this.
The [email protected] team has plenty going for it. It's been around a lot longer and has accumulated a much larger total number of blocks checked. They have openly stated that they will donate the entire $1000 to Linux International if they win. They seem to have two sets of Web pages and you can access the second set here.
The Team Linux group have stated that they will donate all of any prize money or other revenue directly to a Linux group of the members' choosing. Any administrative costs will be paid for out of our own pocket. Since Team Linux is also involved in the Cyberian effort, the prize money may very well be $5000US for Team Linux, or $1000US if the key is found through the Bovine effort.
Team Linux is also in discussion with several companies about up-ing the anti, possibly by having them match the prize money available, or perhaps some other method which does not rely on chance nearly as much. We should have an announcement on this soon.
We would like to encourage you to get involved in either team
and compete in the spirit of Linux, for the benefit of Linux.
As long as the competition remains friendly, it will be healthy and help out.
The Future of Distributed Computing
Getting tens of thousands of computers working on a common problem is an awesome technical accomplishment. It is made all the more interesting by the fact that the computers are spread out world-wide, some of them available full-time, some not, with different hardware and operating systems. Having them all owned by different people and organizations, each with their own agenda and motivations adds yet another dimension to the task.
Some papers and sites on the topic of distributed systems and related subjects which we've found:
- Condor is a project at University of Wisconsin-Madison which has been going on for about 10 years. They have published a number of interesting papers on what they call High Throughput Computing (HTC). They are the movers and shakers for the third group working on the RSA Challenge called Infinite Monkeys.
- Yahoo have a whole section devoted to distributed computing. There is a good collection of material here, with many universities being represented.
- The GREAT Internet Mersenne Prime Search is another way to use those spare cycles.
- In Search Of The Optimal 20 & 21 Mark Golomb Rulers
- SETI@home is an effort to use spare cycles in the Search for Extra-Terrestrial Intelligence (SETI). It looks like this might ramp up to be a very big thing by next Spring. They are looking to put hundreds of thousands of machines to work. Let's make sure they do a Linux client program!
- As we all know, lots of cool research has come from the folks at Xerox PARC (Palo Alto Research Center), including probably the first windowing environment. It's not surprising to find that they have a number of papers on the subject. There is one which looks particularly interesting in a section called allocating time on idle computers: C. A. Waldspurger et al., Spawn: A Distributed Computational Economy, 1992. Unfortunately, it has been taken off-line. I seem to recall something like this published some years ago, possibly in Byte, although no reference could be found.
While researching the Xerox PARC site, we came across a section called the Dynamics of Computation Area. You have to see this, if for no other reason, to see the graphic depicting many small distributed efforts overtaking one large effort!!
Do it now!!It's easy. You'll have plenty of help. And once you are set up, you can let your system do the rest!

 Randy Appleton
Randy Appleton
Larry Ayers
Gerd BavendiekJohn DailyJim Dennis
Bill Duncan
John Fisk
Sam Trenholme
Thanks to all our authors, not just the ones above, but also those who wrote giving us their tips and tricks and making suggestions. Thanks also to our new mirror sites.
 My assistant, Amy Kukuk, did all the work again this month.
She's so good to me. Thank you, Amy.
My assistant, Amy Kukuk, did all the work again this month.
She's so good to me. Thank you, Amy.
Our beautiful new logo was designed by our very own Graphics Muse, Michael J. Hammel. (He used The Gimp.) Thanks, Michael.
Well, this is the last issue that Amy and I will be working on. We are turning over the editorship to Viki Navrotilova. Here's a bit about Viki:
Viktorie Navratilova has been using Linux for the past 4 years, and has been active in both the Israeli and Chicago Linux Users' Groups. She started using Linux because of its network capabilities, and then stayed for the compilers.
I know Viki will have as much fun as we have and do a wonderful job. Show your support and send her lots of articles.
LG will remain under the guardianship of Linux Journal and neither the web address or e-mail address will change. Articles from LG will continue to appear in LJ.
Have fun! Bye-Bye!
Marjorie L. Richardson
Editor, Linux Gazette [email protected]
Linux Gazette Issue 21, September 1997, http://www.ssc.com/lg/
This page written and maintained by the Editor of Linux Gazette,
[email protected]



 The Mailbag!
The Mailbag!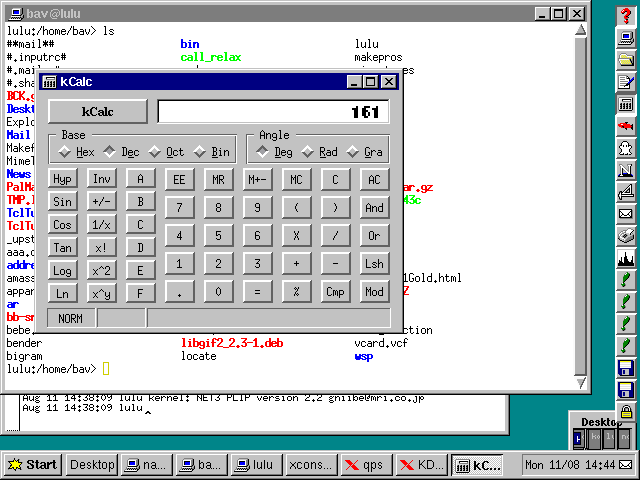{kind=link}